作者:李晶阳[1],牛广林[2],唐呈光[1],余海洋[1],李杨[1],付彬[1],孙健[1]单位|阿里巴巴-达摩院-小蜜Conversational AI团队[1],北京航空航天大学计算机学院[2]摘要行业知识图谱是行业认知智能化应用的基石。目前在大部分细分垂直领域中,行业知识图谱的 schema 构建依赖领域专家的重度参与,该模式人力投入成本高,建设周期长,同时在缺乏大规模有监督数据的情形下的信息抽取效果欠佳,这限制了行业知识图谱的落地且降低了图谱的接受度。
本文对与上述 schema 构建和低资源抽取困难相关的最新技术进展进行了整理和分析,其中包含我们在半自动 schema 构建方面的实践,同时给出了 document AI 和长结构化语言模型在文档级信息抽取上的前沿技术分析和讨论,期望能给同行的研究工作带来一定的启发和帮助。
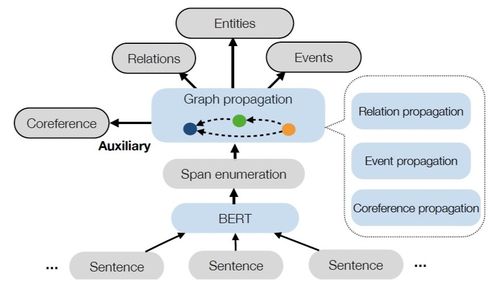
引言从计算到感知再到认知的人工智能技术发展路径已经成为大多人工智能研究和应用专家的共识。机器具备认知智能,进而实现推理、归纳、决策甚至创作,在一定程度上需要一个充满知识的大脑。知识图谱[4, 18, 19],作为互联网时代越来越普及的语义知识形式化描述框架,已成为推动人工智能从感知能力向认知能力发展的重要途径。
知识图谱的应用现在非常广泛:在通用领域,Google、百度等搜索公司利用其提供智能搜索服务,IBM Waston 问答机器人、苹果的 Siri 语音助手和 Wolfram Alpha 都利用图谱来进行问题理解、推理和问答;在各垂直领域,行业数据也在从大规模数据到图谱化知识快速演变,且基于图谱形式的行业知识,对智能客服、智能决策、智能营销等各类智能化服务进行赋能。
1. schema构建知识图谱 schema 构建是构建知识图谱的首要步骤,但同时也是非常影响项目快速推进的环节之一。在基于知识图谱的应用在各类行业中落地的进程中,大部分行业没有接触过知识图谱,因而没有沉淀行业内的知识 schema 用以构建行业图谱。同时由于知识图谱的概念较新,行业业务专家需要一个从理解到熟练构建 schema 的过程,而此过程往往还需要算法人员的频繁介入。
如此在一个新的行业中落地图谱相关的应用时,按照我们的项目经验,完整的 schema 构建往往需要消耗周级甚至月级的时间单位。RSN 模型 [8] (见下图)在已有的关系标注数据上,基于 CNN 模型训练了句子之间的语义匹配模型,并将此模型用于计算测试数据中句子之间的相似度矩阵,进而利用基于图的聚类算法 Louvain 进行不固定聚类类别的聚类。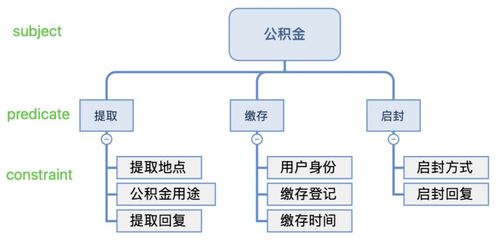
RSN 模型在半监督、远程监督的关系识别任务上都取得了很好的效果。
此类模型受限于已有的实体识别和句法分析工具或者需要先验的标注数据进行更加精准的聚类,且其仅对关系进行聚类但没有进行显式的抽取。由于大规模标注数据很难获取,RnnOIE-SupervisedRL [73] 模型(见下图)首先基于句法和语义规则自动进行大规模抽取,在此数据上训练 RnnOIE 模型,得到初步的抽取模型。为了增强模型的准确性,RnnOIE-SupervisedRL 对前述初步抽取模型,采用强化学习的训练机制进行了进一步训练,其 reward 是由抽取结果的基于 head match 的句法满足度和基于 Bert 的预训练模型给出的语义匹配度的乘积得到。
实验证实,上述模型在 OIE2016 数据集上的 F1 值由 20.4% 提升到了 32.5%,两个子模型分别贡献了约 4% 和 8% 的提升。上述模型目前所考虑的 SPO 形式还较为简单,对于复杂情形(如包含一个 SP,多个 O 的句子)的处理还需进行深入研究。1.2 半自动schema构建在基于知识图谱的问答(KBQA)中,我们实现了基于问句的半自动 schema 构建。以公积金场景为例,下图展示了公积金图谱 schema 的一部分,算法做的是从用户的大量问句中抽取“公积金”为 subject,“缴存”、“提取”、“启封”为 predicate。
同时由于实际中涉及一些复合类型属性(compound value type),比如“提取”属性是复合类属性,因其含有限制属性“提取地点”和“公积金用途”。如后面基于 GNN 的抽取图所示,算法是从问句集中抽取(公积金,抽取,租赁住房),再由业务方校验和进一步抽象为(公积金,抽取,公积金用途)。因此,算法最终要从问句中抽取出 subject, predicate 和 constaint 三部分,分别对应前述例子中的 “公积金”,“抽取”和 “租赁住房”。基于 GNN 的抽取我们发现上述方案没有很好的考虑各类依存句法逻辑之间的综合关系,且泛化性能有限。
因此,在上述方案基础上,设计并实现了将聚类簇图结构化,并借鉴知识图谱上图卷积神经网络方法进行建模的方案。为了达到领域无关的效果,图结构中节点的 embedding 表示是基于词汇在簇词汇集中的位置 onehot 表示生成得到。从实际效果来看,基于 GNN 的模型相较于第一个版本的模型具有更好的泛化性和准召率。下图给出和(公积金,提取,租赁住房)相关的聚类簇图结构化的展示例子。
2.4.2 知识增强的模型(1)词汇增强对于中文任务来说,句子中的词汇信息显然是重要的,但是先对句子进行分词,在词序列的基础上进行序列标注任务,这种 NER 模型架构的效果受限于分词的准确性。因此,如何将句子中的词汇信息合理的整合到基于字的序列标注模型中,是中文 NER 主流研究方向之一。Lattice-LSTM [24] 将句子表示为由其中的词汇和字构成的 Lattice 结构(见下图)。
在基于字序列的 LSTM 基础上,Lattice-LSTM 仿效 LSTM 的信息传递机制,将词汇的信息整合进该词汇的首尾字符的表示中。如此模型便将字符级信息和词汇级信息进行了有机的融合,既丰富了模型的语义表达,又使得模型对分词带来的噪声有很好的鲁棒性。在中文数据集 MSRA [13] 和 WeiBo [14] 上,Lattice-LSTM 的 F1 值相较于基于字符和基于词汇的模型的最好性能均有 2% 以上的性能提升。
FLAT [26] 在融合字符与词汇的 Lattice 结构上,引入 Transformer 来进行建模。相对于上面以 RNN 和 CNN 为基础架构的模型,FLAT 能整合更加长程的信息的同时,还能更充分的利用 GPU 资源进行并行化训练和推理。其主要模型点在于:将 Lattice 结构按照字符的位置以及词汇的头尾字符的位置重构为序列结构;由于 Transformer 所利用的绝对位置向量编码无法很好的建模序列中的顺序信息,因此,FLAT 根据词汇之间的头尾,头头,尾头,尾尾字符距离定义了四种距离,并且对这四种距离进行向量编码。考虑字符/词汇与其他字符/词汇的向量表示,以及距离的向量表示进行权重计算,最终得到相应的 attention。
在中文数据集 MSRA [13] 和 WeiBo [14] 上,FLAT 相较于 LR-CNN 的 F1 值分别有 0.6% 和 3% 的性能提升。2.4.3 半监督模型半监督算法旨在在有标签和无标签的数据集上对模型进行建模(整体模型分类见下图)。利用无标记数据进行神经网络半监督学习,在 NER 领域中得到了广泛的研究。
区别于 NCRF-AE 将标签信息直接建模为隐变量的方式,VSL-G [30] 通过引入纯粹的隐变量及隐变量之间的层次化结构,并且利用 variational lower bound 来构建重构损失函数,从而将有监督损失和无监督损失函数独立开来。此模型的重要意义在于引入并设计了隐变量之间的层次化结构,在此基础上引入的 VAE 下界损失对于有监督模型中参数起到了很好的正则化作用,从而达到了在小型数据集上就训练就有很好的泛化性能。相比于 LADA 在隐向量层面进行数据增强,ENS-NER [32] 模型采用在词向量上添加高斯噪声的统计学数据增强手段,以及随机掩盖 token 和同义词替换的语言学数据增强手段,从而达到数据增强效果。在相关数据集上的实验证实此类数据增强对于 NER 是有增益的,而且语言学数据增强和统计学数据增强手段的效果相当的。
值得注意的是,除 BERT 等语言模型之外,以上几类半监督模型在原有标签数据量占原有训练集较小比例时,如 10% 左右,其效果是明显的,但是当原有标签训练数据占比变大时,非原有标签数据给模型带来的增益并不明显。2.4.4 复杂实体前述模型主要针对连续实体的抽取进行建模,在实际应用中还存在部分复杂实体的识别问题。这里的复杂指的是存在不连续的单实体以及多实体之间的覆盖和交叉关系。
下图分别给出不连续实体(discontinuous entity),嵌套实体(nested entities)和 交叉实体(overlapping entities)的例子。更多地,[35] 引入句子的 hypergraph 结构表示来解决多类别实体嵌套和不连续识别问题,相较于经典模型的序列预。
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报