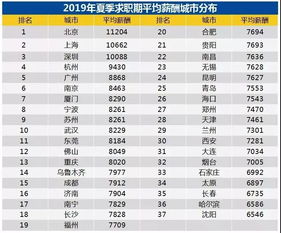
本文涉及的 paper 我大都写过 reading note 并发表在知乎上,欢迎评论区讨论!背景及引入自渲染方程提出之后,关于渲染的算法都是在研究如何更快计算渲染方程。考虑渲染方程,最难算的是积分部分
int L f|cos theta_i| dw_i
当使用蒙特卡洛算法计算这个积分式时,需要有一个采样概率。采样概率 pdf 与被积函数的形状越像,收敛速度越快。

极端情况下,当 pdf 就是被积函数的常数倍时,一次采样就可以收敛到真实解。现在最常用的是,对 brdf 和 cos 进行重要性采样,即
ppropto f|cos theta_i|
在实时渲染中,还会考虑 visibility 项之类的,此处略过。容易发现,传统的重要性采样方法是略过L
这一项的,无论是光子映射算法,还是同时结合 photon 和 path 的 VCM 。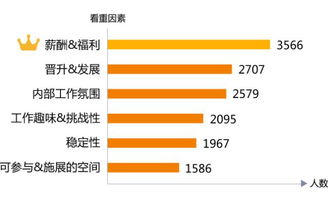
原因就是这玩意太难算了,你得递归下去。
现在的渲染加速大体分为两派,在近几年非常火爆:
- 渲染去噪。使用极低的采样率,获得一个极高噪声的渲染图像,然后使用重建算法进行修复。常见于实时渲染。
- 路径引导。在渲染前采样大量样本,让估计
L
成为可能,对其有充分的估计后再进行重要性采样。
此后的收敛速度会大大加快。常见于离线渲染。
后者也有了一些产品级应用 [9]。它的优点是依然保持无偏,对 GI 支持更好,但缺点就是需要提前大量采样,对内存和计算量消耗很大。本文是笔者对近几年 path guiding 算法的一个调研与学习总结。首先介绍一下 path guiding 的基本思路与使用方法;然后介绍它的优化目标;之后从 path guiding 的几个特点入手,穿插介绍近几年的工作;最后发表一下感想。
介绍path guiding 旨在拟合概率分布
ppropto L|cos theta_i|
即对于采样点 x,对下一步的递归方向,可以有一个 radiance 上的重要性采样(有时 cos 项放到这里,有时放到 brdf 那里)。至于方法,就是狂采样本,当在场景表面积累的样本足够多时,这个 radiance 就可以被估计出来了。这里强调两个特点:- 大量采样
- 在场景表面存储 radiance pdf
这很容易让人想到 Metropolis Light Transport 算法。MLT 使用马尔可夫链理论,通过不断迭代找到贡献最大的路径,还有它对应的概率。同为在路径空间上的重要性采样,MLT 和 Path Guiding 的理论框架是不同的:Path Guiding 基于传统蒙特卡洛算法理论框架,容易与大部分 path tracing 算法相结合;而 MLT 基于 MCMC 算法框架,基本自成一派。这也导致二者的算法设计角度不同:Path Guiding 考虑到是如何更快更好的拟合 radiance pdf;MLT 是在小心设计马尔可夫转移方程。
如何使用 Path Guiding如果 path guiding 算法可以支持 product sampling,即如果可以得到
ppropto Lf|cos theta_i|
那么大功告成,这个东西就是最优的采样概率分布。如果不能支持,那需要对 path guiding 的 pdf 与 brdf 的 pdf 做多重重要性采样。注意,并不是所有算法都能支持 product sampling,这与 radiance 的表示有关。因为 brdf 有 wo 项,每次采到时才能计算,radiance 的表示必须支持快速查询乘积后的 pdf。这是有办法解决的,比如用某些参数模型表示。如果用显式的 image 或者数据结构表示,那么需要 per pixel 去查询乘积,这是低效的,一般不会这么做。
目前大多算法都不支持 product sampling。[1] 是一个反例,它采用 VMM 参数模型进行自适应 radiance pdf 拟合,可以推导出 product sampling。Path Guiding 的优化目标如果是对 brdf 做重要性采样,因为这玩意是确定的,所以重要性采样参考的函数也是确定的,这完全没有问题。但是,如果是对 radiance 进行重要性采样,因为这个 radiance 也是估出来的,估计的解自然带有方差,如果不考虑这个方差,那么得到的 pdf 不是最优的,因为参考的函数是有误差的。
混合样本因为计算 pdf 跟计算 radiance 直接挂钩,所以实际上 guiding 时计算 radiance 的准确性也会直接影响 pdf 的收敛速度。这有点鸡生蛋蛋生鸡:我做 guiding pdf 是为了让渲染快速收敛,但是只有 radiance 收敛的快 pdf 才收敛的快。不过这也是没办法的事。
所以,就像 VCM 混合了光子和路径会带来好处,guiding 时的采样样本使用混合光子和路径的样本,自然会带来好处。[6] 采取的就是这样的方法。它把采到的混合样本集成到一个 pdf 内,达到了更好的效果。不过按道理来讲,如果有一些区别对待,效果会更好。
PDF 的表示与存储不管怎样,我们采到的总是某个 x y z 范围内(因为要用 kdtree/voxel 组织)二维方向域上的若干点,点上会带有它的 radiance。我们有这些离散点,需要用他们来表示 pdf 。[7] 是一篇 1995 年的工作,他直接在方向域上画格子,在格子上累计,形成了一个直方图,用这个直方图来表示 pdf。
[4] 同样考虑在方向域上画格子累计,但是使用四叉树来维护,因为通常这个分布是不均匀的,有大面积空白,也就是稀疏的。使用稀疏数据结构维护可以自适应分辨率。[1] [3] 是参数化方法,使用参数模型(例如 [3] 是混合高斯模型)来拟合样本点形。
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报