阿尔法公社━━━━━━重度帮助创业者的天使投资基金
阿尔法公社说:时至今日,传统的CPU甚至GPU已不能够满足深度学习算法所带来的运算效率需求,由此,人们开始设计各种新型的计算硬件,基于存内计算的计算硬件应运而生。本文主要介绍北京大学人工智能研究院研究员燕博南等人的研究:存内计算(PIM)怎么去突破冯诺依曼瓶颈(Von Neumann Bottleneck),它是怎么实现的。近年来,随着深度学习算法的广泛应用,人工智能方兴未艾,AI相关技术的应用也越来越丰富。

伴随着AI发展一起到来的,则是对硬件性能要求的不断提升。时至今日,传统的CPU,甚至GPU已不能够满足深度学习算法所带来的运算效率需求,由此,人们开始设计各种新型的计算硬件,基于存内计算的计算硬件应运而生。本文主要介绍了北京大学人工智能研究院研究员燕博南等人关于存内计算的研究,大致可以分为两个部分:一,纯硬件上如何设计Hardcore IP;二,基于Hardcore IP如何完成从硬件到软件的接口。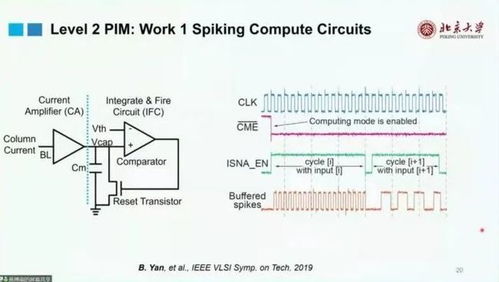
存内计算简介近年来,随着深度学习算法的广泛应用,AI相关技术在各种规格的平台上的应用也越来越丰富。
而深度模型在部署前需要预先进行训练,然后将待处理数据直接输入模型得到结果,运算时,这些AI算法会造成存储单元与计算单元之间大量的数据吞吐,因此需要进行相关加速。而传统的CPU,甚至GPU都不足以满足这样的性能需求,由此,人们开始设计各种新型的计算硬件。这些硬件主要的应用原理是 Systolic Array(脉动列阵),在这种阵列结构中,芯片上的数据按预先确定的“流水线”在计算单元之间流动,这个过程中,所有的处理单元(PE)同时并行地对流经它的数据进行处理,因而它可以达到很高的并行处理速度。
通过研究发现,片上的数据读写(On-Chip Buffer)所需要的能量远低于与片外数据进行交互时所需的能量,为了减少能耗,人们希望尽量减少与片外的数据交互,基于存算一体化技术的计算硬件正是在这种背景下被设计出来。什么是存内计算传统的冯诺依曼体系包括存储单元和计算单元两部分:存储器保存程序和数据,计算单元负责数据的处理。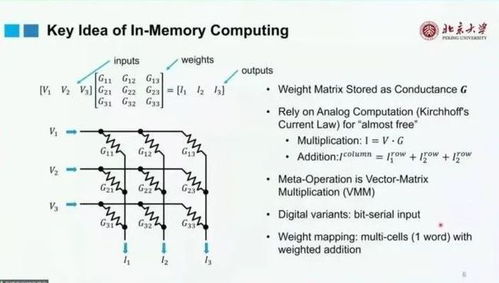
运算时,数据在两个单元之间的流动所产生的延迟和能耗,是当前影响计算机总体性能和功耗的瓶颈因素。
近年来,存储器容量迅速增长,而存储器与计算单元之间的数据吞吐带宽增长有限,形成了冯诺依曼瓶颈(Von Neumann Bottleneck)。随着技术的进步,不断有新型架构出现,如近存计算(Near-Memory Computing),来尝试解决冯诺依曼瓶颈,而一种最为理想的架构则是存内计算(PIM)。PIM(Processing-in-memory,也被称为In-memory Computing 或存内计算),指的是在存储器内部直接进行数据处理的技术。
理想情况下,PIM可以有效消除存储单元与计算单元之间的数据吞吐,且不受能耗比重的制约,从而有效解决冯诺依曼瓶颈。随着内存价格的下降以及依赖固定计算模型的应用的大量出现,PIM越来越受到学界和工业界的重视。为了实现存内计算,首先需要更新底层电路,以达到支持相应功能的目的。这是一个全新的领域。
存内计算的运行原理目前比较流行的存内计算范式是——利用存内计算加速VMM(Vector-Matrix Multiplication)或GEMM(General Matrix Multiplication)运算。具体的计算原理如下:这三个层次与现有的存储技术相似,如,第一层级的SRAM,读写速度快,计算延时短,但是存储量级小;第二层级的非嵌入存储器,如RRAM和MRAM,读写速度稍慢,但存储量级变大,计算延时较短;而第三层级,如PCM,Flash,读写更慢,计算延时也更长,但相应的存储量级也是最大的。要实现上述分级,硬件上,需要提高计算效率,以更少的功耗实现更高的性能;软硬件接口上,则需要提高硬件的可编程性,使编译人员也能享受到硬件性能提高带来的福利。在进行利用率对比之后,可以发现,通过优化,芯片在时间与空间的利用率都达到了95%以上。
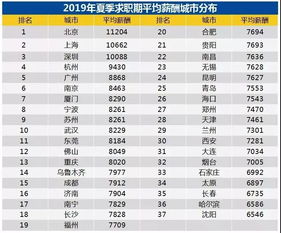
基于Level 2 PIM的硬件设计RRAM 具有更高的Density,且调用之后数据不会消失,这一特点对设计基于片上RRAM进行存内计算的帮助很大。而在Read-out Circuits方面,由于现有的存内计算的模数转换器(ADC)相对面积较大,希望通过在芯片上放置更多简单小电路的方法,在保证性能的同时缩小ADC的面积。用Spiking-based 计算电路代替传统的Current-based ADC。这种计算电路可以收集输入的计算结果,并充入一个固定的电容,当达到一定阈值后,电容会释放电流,从而形成类似于神经脉冲的形式。
由于电流越大,充电速度越快,导致形成pulse的频率不同,最后接计数器来完成数字的转换。电路图原理如下:存内计算的软着陆SOC系统简介器件可以形成Bitcell Array,与传统的控制电路(如decoder等)组合形成传统的Macro;而存内计算则是在此基础上,再加入计算电路,形成一个基础的PIM Macro。然后将PIM Macro放入系统,形成独立的加速器(PIM Accelerator)。
最后,将加速器放入系统级芯片(SOC)。由整个系统的结构可以看出,存内计算目前只是改变最底层的电路,理论上并不会彻底改变整个SOC。从硬件到软件接口改变了硬件的加速器之后,需要出现相应的软件接口。
为此,需要利用能直接控制PIM Accelerator的编程语言,编译的入口为常用的编译模型,如PyTorch,TensorFlow等。目前,一种比较流行的片上的SOC模式是:CPU+加速器+SRAM等存储器。相较于传统的存储模式,PIM Accelerator可以与众多加速器一起放入系统之中,与其他加速器共同分享数据,但目前这个开发流程比较难以实现。PIM在应用过程中面对的挑战有三:传统的NPU规格大,针对如TinyML这种小型应用场景的适应性不强,且成本较高,不能满足相应的市场需求;开发出包含从PIM硬件的发展到编译、再到软件接口的全流程技术栈难度大、耗时长;PIM硬件虽然可以定制,但很难直接推广到软件编译人员中去。
基于以上挑战,燕博南课题组提出新型的“异构存储器层级”尝试直接在SoC上应用PIM Macro的硬核IP:将PIM作为存储器,并给它添加上传统的接口(如HP接口),从而将它接入现有的Memory base(需要带宽足够)。这样可以利用主控CPU兼容PIM存储器的接口,来完成相关编译。与传统SRAM相比,PIM存储器需要单独的Input Buffer,计算结果也需要独立的Virtual Output Buffer存储PIM的计算结果。
在这个设计中,PIM存储器将成为系统的一部分,此时,整个存储空间(Memory Space)被称为Heterogrnous Memory Space,这样的存储空间可以直接利用最基本的load-store指令进行操作,完成存储任务和计算任务,从而避免为PIM Accelerator单独设计硬件,编译器,以及相关编程等等。同时,他们也尝试开发关于软硬件接口的一个C语言数据库。通过较高层次的编译,把C中最初输入的矩阵转化成可识别的数据存入库。如此一来,针对一些不足以放下加速器的小应用场景,可以放入PIM存储器代替,以优化整个设计流程,从而实现算力上的巨大飞跃。
实际上,通过测试可以发现,将PIM作为存储器放入SOC中做计算时,Memory base 的带宽是足够的。对PIM的展望自2018年以来,学术界中进行流片测试的PIM存储器原型设计规模越来越大,逐渐接近实际应用中的存储器容量;同时,也有越来越多的公司开始制造存内计算相关的硬件,软件,并进行各种商业化的尝试,工业界对存内计算的认可度越来越高。值得注意的是,PIM存储器与其他存储技术之间并没有很强的竞争关系,所以在未来很长一段时间内,市场中的主流存储模型将会是各种存储技术与PIM混合的架构。
本文授权转载自智源社区,讲者燕博南,整理牛梦琳。关于阿尔法公社阿尔法公社(Alpha Startup Fund)是中国。
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报