文章目录
- 🐨前言
- 🐨项目说明
- 🐨步骤讲解
- 🐨全程操作讲解
🐨前言
以上得几期内容我们就把所有得计算机视觉得基础相关处理介绍完了,然后我们这里以几个小项目来继续巩固一下前面得基础知识。其实我们本次博客做的银行卡号识别和车牌识别、快递单号识别等等项目之间都是相通的,所以我们掌握了本节课得相关知识,就相当于把很多项目得思路掌握了!我们开始今天得项目讲解吧。

🐨项目说明
项目目标:我们导入一张银行卡或者信用卡得图像,通过OpenCV来把它实现出来,把信用卡得数字(卡号)给识别出来。
首先我们需要一个数字模板,比如下面这两种,这里对应得项目不同,我们需要得模板也是一定不一样得,那么这个模板有什么用呢?就是说我们要使用OpenCV去识别银行卡上的数字,但是我怎么让计算机认识这些数字啊,是不是得让他学习啊,让计算机通过学习之后,他知道究竟哪个是1,哪个是2。通常的模板都有车牌模板


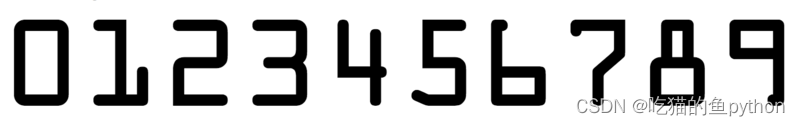
我们利用学习过的模型去和信用卡上的数字一一匹配,我们就是要做一个这样的事情,然后对于每一次匹配结果我们让计算机给打一次分,比如我们传进来一个图像,他是8,他首先用1去匹配,给出32分,2给出18分,8给出了88分。最高那么我们计算机就认定这个数字为8。然后找到对应模板上的索引(这里进行一下说明,这个模板的数字的型号和样子要和目标一致。)这里我们就需要用到resize这个操作,把提取出来的东西进行resize操作。
🐨步骤讲解
1.使用模板匹配方式对模板,以及输入图像进行轮廓检测(检测外轮廓)。
2.得到当前轮廓的外接矩形。
3.将模板中的外接矩形切割出来。
4.使用矩形的长宽比之间的差异使得信用卡的数字矩形框能够被选择出来。
5.将其进一步细分,与需要识别的信用卡当中的外接矩形resize成同样的大小。
6.使用for循环依次检测。

🐨全程操作讲解
我们再说明之前,先说一下学习代码不管学习什么语言吧,一定要会的一个操作就是DEBUG这个操作,会帮助你阅读代码,省时省力。比自己一行一行的去阅读,而且你也记不住哪块得到的结果是什么,DEBUG一个操作帮助你全部搞定。对于DEBUG,我们使用pycharm就是打上断点,一般就是在主程序if __name__=='__main__': 这里下方打上断点,然后按照他的指引一步一步的去看代码。非常实用!!!
然后我们直接进入代码,首先我们来看一下要操作的图片。

首先我们要定义一个绘图的函数,这样方便后期的绘图操作。要不然每次出图都要进行相同的操作,比较麻烦。
def cv_show(name,img): cv2.imshow(name,img) cv2.waitKey(0) cv2.destroyAllWindows()然后我们导入第三方库和输入参数操作:
其中imutils库,它整合了opencv、numpy和matplotlib的相关操作,主要是用来进行图形图像的处理,如图像的平移、旋转、缩放、骨架提取、显示等等,后期又加入了针对视频的处理,如摄像头、本地文件等。imutils同时支持python2和python3。
在这里定义了银行卡的类型。
from imutils import contoursimport numpy as npimport argparse#用来输入import cv2import myutils#我们定义的一个函数ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", required=True, help="path to input image")ap.add_argument("-t", "--template", required=True, help="path to template OCR-A image")args = vars(ap.parse_args())FIRST_NUMBER = { "3": "American Express", "4": "Visa", "5": "MasterCard", "6": "Discover Card"}这里我们说明一下,对于再pycharm中操作的话,一定要指定输入图片的路径。
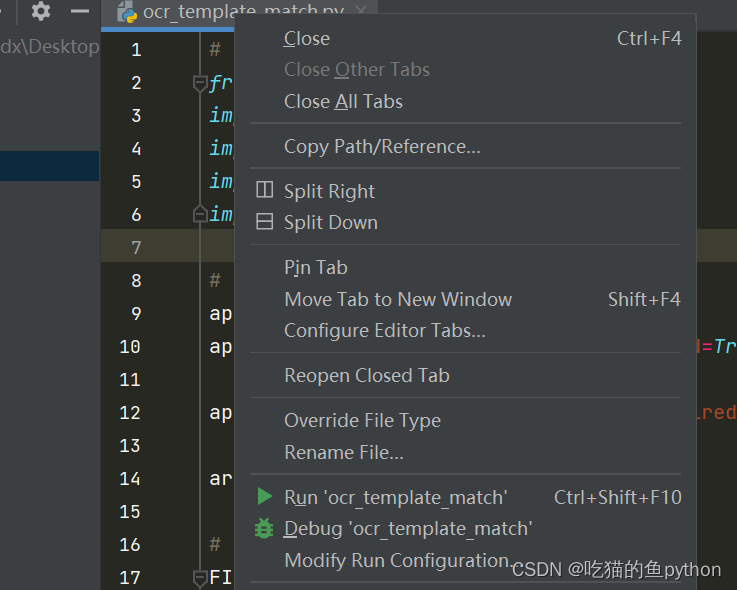
这里我们点击Modify Run Configuration然后指定参数。
在这里进行一个指定,输入-i 然后指定输入图像路径一定要精确到图片,比如123.jpg。然后空格-t 模板的图片。这里有不懂的可以私信问我。
-i C:UsersjzdxDesktopOpenCVxinyongkatemplate-matching-ocrimagescredit_card_01.png -t C:UsersjzdxDesktopOpenCVxinyongkatemplate-matching-ocrimagesocr_a_reference.png在这里的颜色空间转换一共有500多种。
img = cv2.imread(args["template"])cv_show('img',img)ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)cv_show('ref',ref)ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]cv_show('ref',ref)这里我们进行了模板的转灰度操作,然后二值操作,对应的二值结果是:
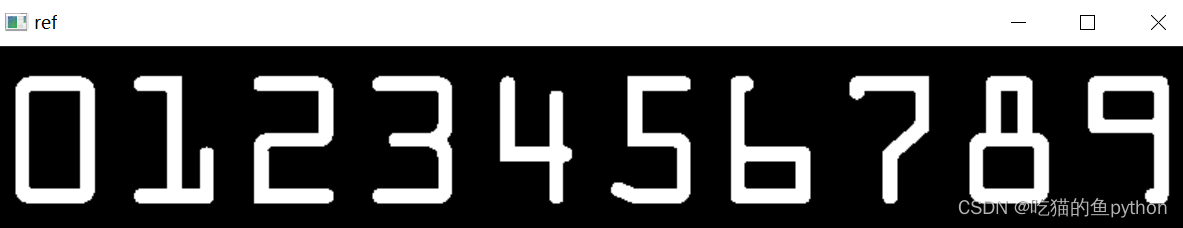
对模板进行轮廓的提取。cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图),cv2.RETR_EXTERNAL只检测外轮廓,cv2.CHAIN_APPROX_SIMPLE只保留终点坐标。这里需要注意的就是,**Opencv老版本返回的是三个参数,而新的版本轮廓检测只返回两个参数。**然后画出指定的外轮廓。
refCnts, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cv2.drawContours(img,refCnts,-1,(0,0,255),3) cv_show('img',img)
提取出来的模板的轮廓。
refCnts = myutils.sort_contours(refCnts, method="left-to-right")[0] #排序,从左到右,从上到下我们对轮廓进行一个排序,那么怎么排序呢,利用轮廓的一个横坐标进行排序,这里我们直接跳进myutils程序当中。
import cv2def sort_contours(cnts, method="left-to-right"): reverse = False i = 0 if method == "right-to-left" or method == "bottom-to-top": reverse = True if method == "top-to-bottom" or method == "bottom-to-top": i = 1 boundingBoxes = [cv2.boundingRect(c) for c in cnts] #用一个最小的矩形,把找到的形状包起来x,y,h,w (cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes), key=lambda b: b[1][i], reverse=reverse)) return cnts, boundingBoxes这里主要就是做了一个轮廓的排序操作,把1就放在1的位置上,没有进行排序是乱的。这里对于排序这个操作是比较常用的一个操作,各位小伙伴要进行掌握。
for (i, c) in enumerate(refCnts): # 计算外接矩形并且resize成合适大小 (x, y, w, h) = cv2.boundingRect(c) roi = ref[y:y + h, x:x + w] roi = cv2.resize(roi, (57, 88)) # 每一个数字对应每一个模板 digits[i] = roirectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))这里对模板遍历了每一个轮廓,进行了resize一下。并且这里定义了两个卷积核。后期后用到。cv2.getStructuringElement设置卷积核的意思。
image = cv2.imread(args["image"])cv_show('image',image)image = myutils.resize(image, width=300)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)cv_show('gray',gray)tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel) cv_show('tophat',tophat) gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, #ksize=-1相当于用3*3的 ksize=-1)这里对传入图像进行了预处理的一个操作,包括转灰度,礼貌操作用来突出更明亮的区域,然后进行了一个Sobel操作。那么Sobel就是说用一个特定的卷积核来对图像进行卷积运算。



再来一个闭操作。**先膨胀再腐蚀!**那么目的是什么呢,我们想让这四块的银行卡号全部都连在一起,然后找到它,提取出来。这就是我的目的。
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel) cv_show('gradX',gradX)thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] cv_show('thresh',thresh)这里得二值操作,是自动找一个适当得数值作为阈值,而不是0.
thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] 这个代码部分要做一下重点讲解,就是他很明显是做一个一个阈值操作,也就是说我们要把图像处理成二值图像,那么我们怎么处理呢?图中不是将阈值设置为0,而是说让计算机自动去识别这个阈值最优是多少!

二值得结果是:

这里就有小伙伴问了,你做的这是啥啊,我们做这些得目的就是要把我们想要的区域拿出来。目前我们发现第一个块和第四块已经连接起来了,中间第二块和第三块还没有连接起来,那么我们再来一次闭运算。
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel) cv_show('thresh',thresh)在进行一个闭操作。因为我们发现有的地方还有黑色得空缺,我们要把他都用255补上,也就是白色。
threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)cnts = threshCntscur_img = image.copy()cv2.drawContours(cur_img,cnts,-1,(0,0,255),3) cv_show('img',cur_img)做完了预处理我们对原图像进行一个轮廓获取。他是使用我们处理之后的二值图像来获取到的轮廓信息。

这么多轮廓,那么我要哪个啊,这里就需要我们进行一个过滤得一个操作。这里根据自己的项目自己而定。估计会试几次。
for (i, c) in enumerate(cnts): (x, y, w, h) = cv2.boundingRect(c) ar = w / float(h) if ar > 2.5 and ar < 4.0: if (w > 40 and w < 55) and (h > 10 and h < 20): #符合的留下来 locs.append((x, y, w, h))locs = sorted(locs, key=lambda x:x[0])output = []首先计算矩形,然后选择合适的区域,根据实际任务来,这里的基本都是四个数字一组。过滤,然后在进行一次排序。
通过过滤操作我们就只剩下了这个部分,但是这里是分为四个部分得,4000,1234,5678,9010.
for (i, (gX, gY, gW, gH)) in enumerate(locs): # initialize the list of group digits groupOutput = [] group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5] cv_show('group',group) group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] cv_show('group',group) digitCnts,hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) digitCnts = contours.sort_contours(digitCnts, method="left-to-right")[0]对这四个地方遍历,然后再次进行图像得预处理,包括灰度,二值,轮廓,排序,然后找到4个数字中得一个一个显示出来。
for c in digitCnts: (x, y, w, h) = cv2.boundingRect(c) roi = group[y:y + h, x:x + w] roi = cv2.resize(roi, (57, 88)) cv_show('roi',roi) scores = [] for (digit, digitROI) in digits.items(): result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF) (_, score, _, _) = cv2.minMaxLoc(result) scores.append(score) groupOutput.append(str(np.argmax(scores)))遍历这些数字之后,我们和模板中得进行一个比较,然后得出一个最优秀得结果。
最后我们将得到的分数再原图像中打印出来:

完美!!!这就是我们做银行卡识别小项目得所有内容,我们为了巩固这个知识后期又做了一下车牌识别得和这个操作大致一致。后期我们会进行更新。

🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报