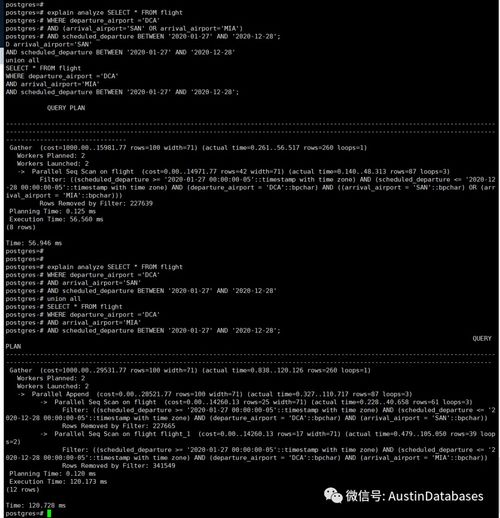
PostgreSQL 有两种父、子表关系:分区(partition)和继承(inherit)。在PostgreSQL中,表分区是内置声明式分区(built-in built-in declarative partitioning),适用于大部分常见用例;另外通过表继承也能实现表分区,而且具有一些声明式分区不具备的特性。
注意:内置声明式分区表(built-in declaratively patitioned table),在不同的地方可能会有不同的叫法,总体上:原生分区 = 内置分区表 = 声明式分区表 = 分区表。内置声明式表分区表的分区就是将一个逻辑上的大表,切分为多个小的物理的分片。分区的优点:1 在某些情况下,尤其是当表中大多数被频繁访问的行位于单个分区或少量分区中时,查询性能可以得到显着提高。分区替代了索引的前几列,从而减小了索引的大小,并使索引中频繁使用的部分更有可能装入内存。


2 当查询或更新访问单个分区的很大一部分时,可以通过对该分区进行顺序扫描而不是使用索引和分散在整个表中的随机访问读取,来提高性能。
直接从分区表查询数据比从一个大而全的全量数据表中读取数据效率更高。3 如果计划将这种需求计划到分区设计中,则可以通过添加或删除分区来完成批量加载和删除。使用ALTER TABLE DETACH PARTITION或使用DROP TABLE删除单个分区比批量操作要快得多。
这些命令还完全避免了由批量DELETE引起的VACUUM开销。
数据维护成本降低。4 很少使用的数据可以迁移到更廉价、更迟缓的存储介质上。
比如:某一部分数据失效,不需要执行命令来更新数据,可以直接解绑指定关系,解除绑定的数据和分区表都依然保留,需要时可以随时恢复绑定。通过 Flyway 等数据脚本管理能够方便的控制数据维护,避免人为直接操作数据。
一个表只能放在一个物理空间上,使用分区表之后可以将不同的表放置在不同的物理空间上,从而达到冷数据放在廉价的物理机器上,热点数据放置在性能强劲的机器上。通常只有在表很大的情况下,这些好处才是值得的。表可以从分区中受益的确切时间取决于应用程序,尽管经验法则是表的大小应超过数据库服务器的物理内存。分区的使用限制:1 无法创建跨所有分区的排除约束。只能单独约束每个叶子分区。
2 因为PostgreSQL只能在每个分区中单独进行唯一性约束;因此,分区表上的唯一约束必须包括所有分区键列。3 如果需要 BEFORE ROW 触发器,则必须定义在单个分区(而不是分区父表)。4 不允许在同一分区树中混合临时和永久关系。因此,如果父表是永久性的,则其分区也必须是永久性的;如果父表是临时的,则其分区也必须是临时的。
当使用临时关系时,分区树的所有成员必须来自同一会话。3种分区策略:PostgreSQL内置支持以下3种方式的分区:
- 范围(Range )分区:表被划分为由键列或列集定义的“范围”,分配给不同分区的值的范围之间没有重叠。例如:可以按日期范围或特定业务对象的标识符范围,来进行分区。
- 列表(List)分区:通过显式列出哪些键值出现在每个分区中来对表进行分区。
- 哈希(Hash)分区:(自PG11才提供HASH策略)通过为每个分区指定模数和余数来对表进行分区。每个分区将保存行,分区键的哈希值除以指定的模数将产生指定的余数。
该规范包括分区方法和用作分区键的列或表达式列表。
创建分区的方法总结:1 创建父表:指定分区键字段、分区策略(RANGE | LIST | HASH);2 创建分区:指定父表、分区键范围(分区键范围重叠之后会直接报错)或DEFAULT;3 在分区上创建索引:通常,分区键字段上的索引是必须的。创建父表:
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name [ INHERITS ][ PARTITION BY { RANGE | LIST | HASH } } [ COLLATE collation ] [ opclass ] [, ... ] ) ]...CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_nameOF type_name [ ][ PARTITION BY { RANGE | LIST | HASH } } [ COLLATE collation ] [ opclass ] [, ... ] ) ]...创建分区:CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_namePARTITION OF parent_table [ ] { FOR VALUES partition_bound_spec | DEFAULT }[ PARTITION BY { RANGE | LIST | HASH } } [ COLLATE collation ] [ opclass ] [, ... ] ) ]....partition_bound_spec is:IN |FROM TO |WITH 父表与分区建立绑定关系ALTER TABLE [ IF EXISTS ] nameATTACH PARTITION partition_name { FOR VALUES partition_bound_spec | DEFAULT }partition_bound_spec is:IN |FROM TO |WITH 父表与分区解除绑定关系:ALTER
TABLE
[
IF
EXISTS
]
name
DETACH
PARTITION
partition_name
;
DROP TABLE [ IF EXISTS ] partition_name [, ...] [ CASCADE | RESTRICT ]RESTRICT:缺省选项,如果有任何对象依赖该表则拒绝删除该表。 CASCADE:自动删除依赖于表的对象(例如视图),然后自动删除依赖于那些对象的所有对象(请参见:5.14 依赖追踪)
参考:PostgreSQL12 Doc - 5.14 依赖追踪:SQL实战:1 创建父表CREATE TABLE measurement PARTITION BY RANGE ; 2 创建分区及子分区--创建分区CREATE TABLE measurement_y2007m11 PARTITION OF measurementFOR VALUES FROM TO ;CREATE TABLE measurement_y2007m12 PARTITION OF measurementFOR VALUES FROM TO TABLESPACE fasttablespace;CREATE TABLE measurement_y2008m01 PARTITION OF measurementFOR VALUES FROM TO WITH TABLESPACE fasttablespace;--创建子分区 sub-partitionCREATE TABLE measurement_y2006m02 PARTITION OF measurement_y2006FOR VALUES FROM TO PARTITION BY RANGE ;3 创建索引在父表的键字段创建索引,以及创建需要的任何其他索引。 (键索引不是严格必需的,但是在大多数情况下它是有帮助的。)这将在每个分区上自动创建一个索引,以后创建或附加的任何分区也将包含该索引。CREATE INDEX ON measurement ;4 确保 postgresql.conf 中的 enable_partition_pruning 启用,否则,查询将不会被优化。在上面的示例中,我们每个月都会创建一个新分区,因此编写一个脚本自动生成所需的DDL可能是明智的。5 维护分区Analyze measurement;声明式分区的最佳实践应该谨慎地选择如何对表进行分区,因为糟糕的设计会对查询计划和执行的性能产生负面影响。最关键的设计决策之一将是用来划分数据的一列或多列。
通常,最好的选择是按在分区表上执行的查询的WHERE子句中最常见的列或列集进行分区。与分区键匹配并兼容的WHERE子句项可用于修剪不需要的分区。但是,您可能会因对PRIMARY KEY或UNIQUE约束的要求而被迫做出其他决定。在计划分区策略时,删除不需要的数据也是要考虑的因素。
整个分区可以相当快地拆离,因此设计分区策略可能有益于将要立即删除的所有数据都放在单个分区中。选择应将表划分为分区的目标数量也是一个至关重要的决定。没有足够的分区可能意味着索引仍然太大,并且数据局部性仍然很差,这可能导致较低的缓存命中率。
但是,将表划分为太多分区也会导致问题。过多的分区可能意味着更长的查询计划时。
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报