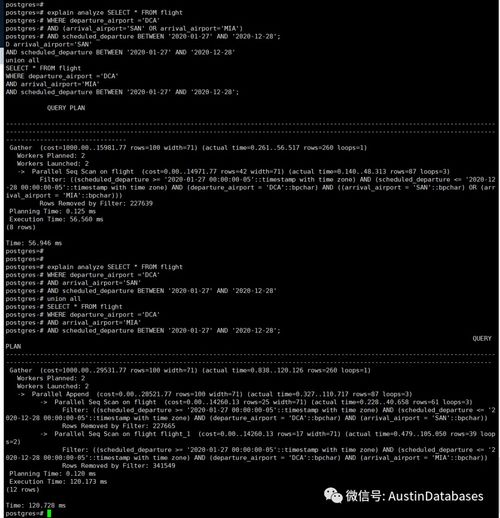
文章目录
- 每篇前言
- 一、爬虫概述
- 1. 为什么要学习爬虫?
- 2. 爬虫与Python
- 3. 爬虫合法吗?
- 4. 爬虫的矛与盾
- 5. 爬虫原理图 and 流程图
- 二、相关技术介绍
- 1. HTML 与 CSS
- 2. URL网址解释
- 3. HTTP 与 HTTРS
- (1)常见请求方式
- (2)常见请求头
- (3)常见请求状态码
- 4. Chrome浏览器分析网站
- 5. Session与cookie
- 6. Ajax请求
- 三、如何让学习更加高效呢?
- 四、书籍推荐
每篇前言
-
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、爬虫概述
1. 为什么要学习爬虫?
对于个人:
-
在浏宽到一些优秀的让人血脉喷张的图片时.总想保存起来留为日后做桌面上的壁纸
-
在浏宽到一些重要的数据时(各行各业),希望保留下来日后为自己进行各种销售行为增光添彩.在浏览到一些奇奇怪怪的劲爆视频时,希望保存在硬盘里供日后慢慢品鉴
-
在浏览到一些十分优秀的歌声曲目时,希望保存下来供我们在烦闷的生活中增添一份精彩
对于爬虫工程师:
-
公司数据需求
-
数据分析
-
智能产品练习数据
2. 爬虫与Python
爬虫一定要用Python么? 非也~用Java也行,C也可以。请各位记住,编程语言只是工具.抓到数据是你的目的用什么工具去达到你的目的都是可以的。和吃饭样,可以用叉子也可以用筷子,最终的结果都是你能吃到饭。那为什么大多数人喜欢用Python呢? 答案:因为Python写爬虫简单。不理解? 问:为什么吃米饭不用刀叉? 用筷子? 因为简单好用!
而Python是众多编程语言中,小白上手最快,语法最简单,更重要的是,这货有非常多的关于爬虫能用到的第三方支持库说直白点儿就是你用筷子吃饭,我还附送你一个佣人帮你吃!这样吃的是不是更卖了。更容易了~
3. 爬虫合法吗?
首先,爬虫在法律上是不被禁止的。也就是说法律是允许爬虫存在的但是,爬虫也具有违法风险的就像菜刀一样,法律是允许菜刀的存在的。但是你要是用来砍人,那对不起,没人惯着你就像王欣说过的,技术是无罪的。主要看你用它来干嘛比方说有些人就利用爬虫+一些黑客技术每秒钟对着bb撸上十万八千次那这个肯定是不被允许的。
爬虫分为善意的爬虫和恶意的爬虫:
- 善意的爬虫:不破坏被爬取的网站的资源 (正常访问,一般频率不高,不窃取用户隐私)
- 恶意的爬虫:影响网站的正常运营 (抢票,秒杀疯狂solo网站资源造成网站宕机)
综上,为了避免进橘子我们还是要安分守已时常优化自己的爬虫程序避免干扰到网站的正常运行,井且在使用爬取到的数据时,发现涉及到用户隐私和商业机密等敏感内容时,一定要及时终止爬取和传播。
4. 爬虫的矛与盾
反爬机制:门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取户网站中相关的数据。个人建议:别强行反反爬,可能会已经涉及恶意爬虫=
robots.txt协议:君子协议,规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。
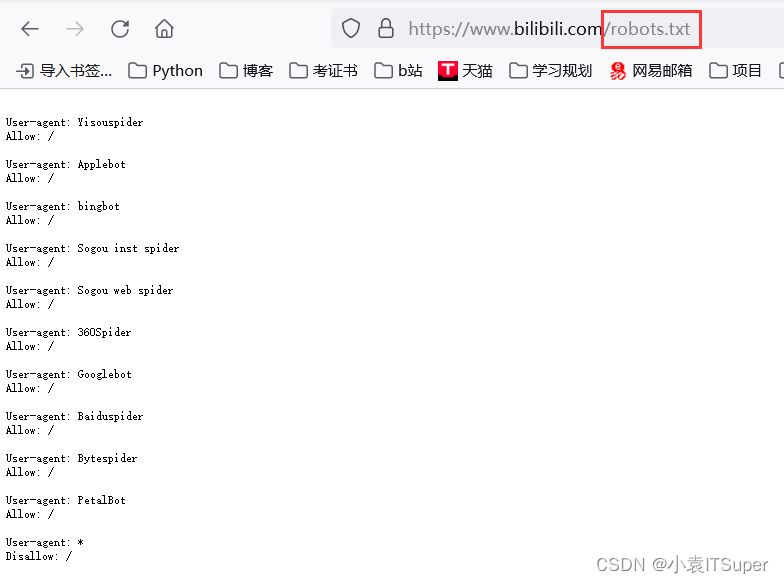
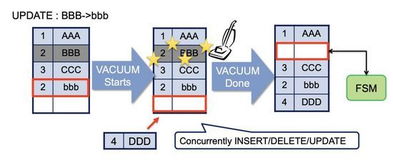
5. 爬虫原理图 and 流程图
爬虫原理图:
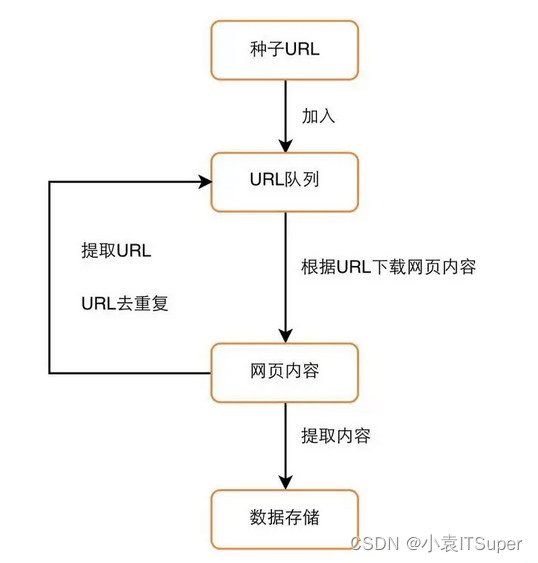
爬虫流程图:
二、相关技术介绍
1. HTML 与 CSS
(1)HTML全称 “超文本标记语言",与程序设计语言有所区别,无逻辑结构,采用标记方式进行网页构建,使用<>将标记括起来
HTML标签如下:
| 标签名 | 说明 |
|---|---|
<p> | 段落标记 |
<a> | 超链接 |
href | 超链接地址 |
<img> | 图片 |
src | 图片存放路径 |
<span> | 行内标签 |
<li> | 列表项 |
<div> | 划分HTML块 |
<table> | 表格标记 |
<tr> | 行标记 |
<td> | 列标记 |
h1~h6 | 标题 |
(2)CSS基础
- 层叠样式表
- 控制HTML页面的样式和布局
- 使用
{}将样式定义括起来
CSS选择器:
- 元素选择器(了解):元素选择器根据元素名称来选择HTML元素

- id选择器(重要):使用HTML元素的id属性来选择唯一特定元素

- 类选择器(非常重要)选择有特定class属性的HTML元素
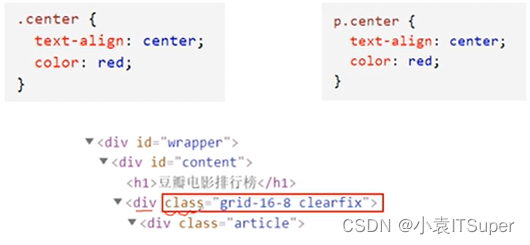
- 案例(选中标题):先找到
div class='p12',在取下面a标签下的文字即可
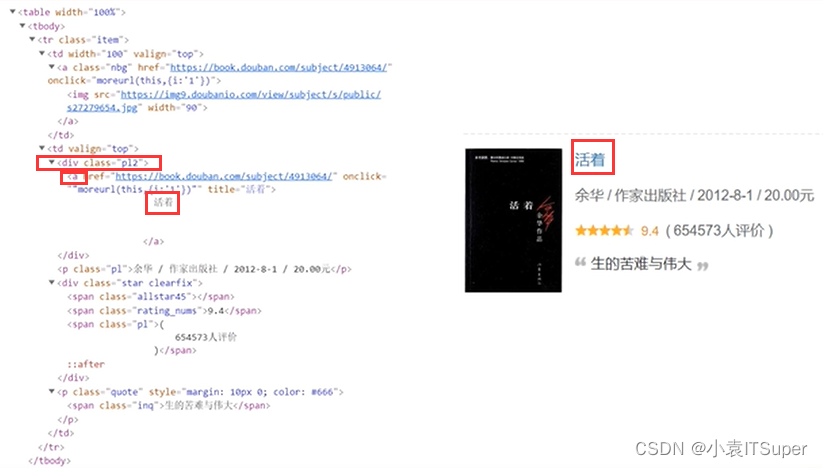
2. URL网址解释
案例网址:https://baike.baidu.com/item/%E8%99%8E/865?fromtitle=%E8%80%81%E8%99%8E&fromid=65781
URL(网址)是Uriform Resource Locator的简写,统一资源定位符。URL由以下几部分组成:
- 1、协议的类型。如:
https - 2、主机名称/域名。如:
baike.baidu.com - 3、端口号
- 4、查找路径。如:
865? - 5、查询参数(为
?后所有内容)。如:fromtitle=%E8%80%81%E8%99%8E&fromid=65781,采用键值对形式,多个键值对用&隔开 - 6、锚点,前端用来做面定位的。现在一些前后端分离项目,也用锚点来做导航
- 前端定位:https://baike. baidu.com/item/*E5488%98%E8%8BKA5%E8%88%B1#2
- 锚点导航:动的是
#之后的内容,根据错点去请求数据 https://music.163.com/#/friend
3. HTTP 与 HTTРS
HTTP协议:全称是HyperText Transfer Protocal ,中文意思是超文本传输协议,是一 种发布和接收HTML (HyperText Markuup Language)页面的方法。服务器端口号为:80
HTTPS协议:全称: Hyper Text Transfer Protocol over SecureSocket Layer,是 HTTP协议的加密版本,在HTTP下加入了SSL层, 服务器端口号是:443
更多知识点参考:图解网络协议
(1)常见请求方式
http协议规定了浏览器与服务器进行数据交互的过程中必须要选择一种交互的方式。在HTTP协议中,定义了八种请求方式,常见的有get请求与post请求。
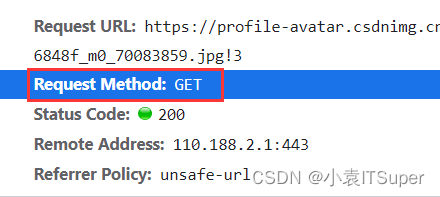
GET请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求
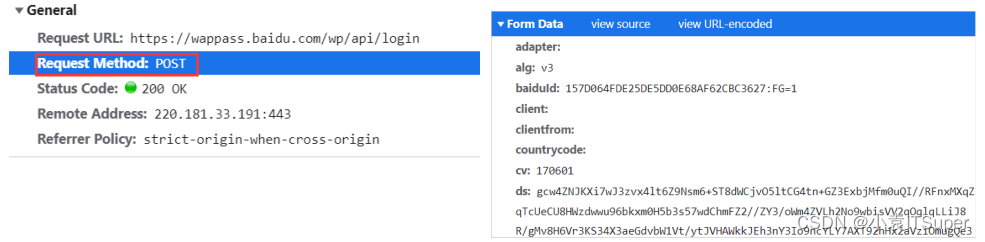
POST请求:向服务器发送数据(登录)、、上传文件等,会对服务器资源产生影响的时候会使用Post请求。请求参数在 Form Data中
(2)常见请求头
http协议中,向服务器发送-一个请求,数据分为三部分:
- 第一个是把数据放在urI中
- 第二个是把数据放在body中(post请求时)
- 第三个就是把数据放在head中
常见的请求头参数:
user-agent:浏览器名称referer:表明当前这个请求是从哪个ur|过来的cookie:http协议是无状态的。也就是同一个人发送了两次请求。服务器没有能力知道这两个请求是否来自同一个人。而带上cookie就识别为登录过的用户或者同一个请求两次
(3)常见请求状态码
- 200:请求正常,服务器正常的返回数据
- 301:永久重定向。比如访问 http://www.360buy.com (京东以前的网址)的时候会重定向到:https://www.jd.com/
- 404:请求的url在服务器 上找不到,换句话说就是请求的url错误.
- 418:发送请求遇到服务器端反爬虫,服务器拒绝响应数据
- 500:服务器内部错误,可能是服务器出现了bug
4. Chrome浏览器分析网站
打开谷歌浏览器:右键 - 》 检查
- Elements:可以帮助我们分析网页结构,获取我们想要的数据
- Console控制台:打印输出网站的一-些信息,比如说网站的招聘信息
- Sources:相当于一个文件夹一样,加载这个网页所需要的所有的源文件,除了Elements的源代码之外,还有一些CSS文件、JS文件等。
- Network:查看整个网页发送的所有网络请求。一般我们想要去查看某- 个请求的信息,都可以到这里面去看

5. Session与cookie
Session与cookie是用于保持HTTP长时间连接状态的技术
Session:
- Session代表服务器与浏览器的一次会话过程。
- Session是一 种服务器端的机制,Session对象用来存储特定用户会话所需的信息。
- Session由服务器端生成,保存在服务器的内存、缓存、硬盘或数据库中。
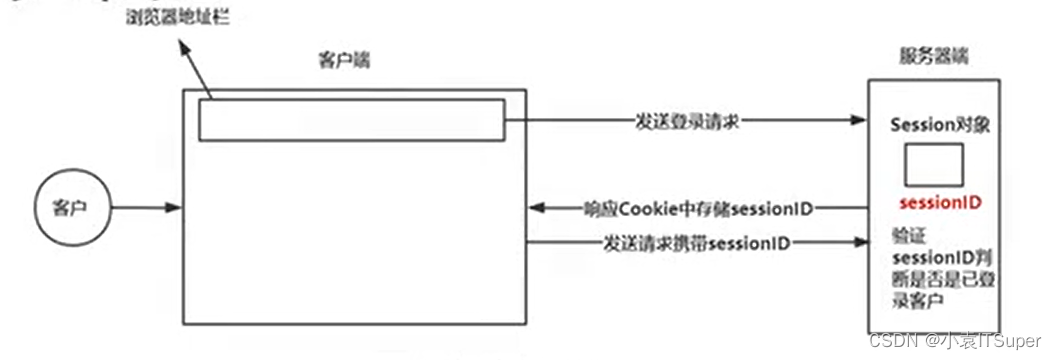
cookie:是由服务端生成后发送给客户端(通常是浏览), cookie总 是保
存在客户端
cookie的基本原理:
- 1、创建cookie
- 2、设置存储cookie
- 3、发送cookie
- 4、读取cookie
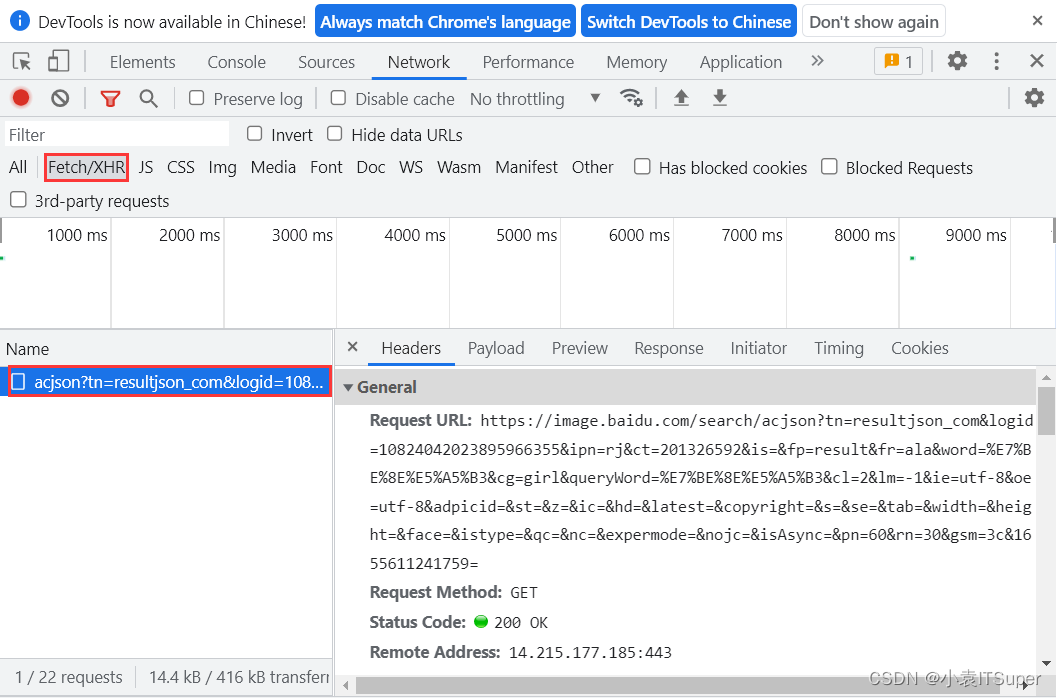
6. Ajax请求
-
Ajax在浏览器与Web服务器之间使用异步数据传输。这样就可以使网页从服务器请求少量的信息,而不是整个页面。
-
Ajax技术独立于浏览器和平台。
-
Ajax一般返回的是JSON,直接对Ajax地址进行Post或get,就返回JSON数据了
-
判断是否为Ajax生成数据,看在滚动网页的时候是否发生了刷新,如果页面没有刷新说明数据自动生成,就是Ajax渲染到界面上的
三、如何让学习更加高效呢?
嫌博主更新慢的小伙伴牛客网上号自行刷题
1. 编程小白选手
很多刚入门编程的小白学习了基础语法,却不知道语法的用途,不知道如何加深映像,不知道如何提升自己,这个时候每天刷自主刷一道题就非常重要(百炼成神),可以去牛客网上的编程初学者入门训练。该专题为编程入门级别,适合刚学完语法的小白练习,题目涉及编程基础语法,基本结构等,每道题带有练习模式和考试模式,可还原考试模式进行模拟,也可通过练习模式进行练习。
链接地址:牛客网 | 编程初学者入门训练

2. 编程进阶选手
当基础练习完已经逐步掌握了各知识要点后,这个时候去专项练习中学习数据结构、算法基础、计算机基础等。先从简单的入手,感觉上来了再做中等难度,以及较难的题目。这三样是面试中必考的知识点,我们只有坚持每日自己去多加练习,拒绝平躺持续刷题,不断提升自己才能冲击令人满意的公司。
链接地址:牛客网 | 专项练习
速度上号,大家一起冲击大厂,有疑问评论区留言解答!!!
四、书籍推荐

【书籍内容简介】
- 随着网络技术的迅速发展,如何有效地提取并利用信息,以及如何有效地防止信息被爬取,已成为一个巨大的挑战。本书从零基础开始讲解,系统全面,案例丰富,注重实战,既适合Python程序员和爬虫爱好者阅读学习,也可以作为广大职业院校相关专业的教材或参考用书。础操作、图形处理基本操作、简单图形的绘制和对象的管理等内容。
- 京东自营:https://item.jd.com/13345900.html
- 当当自营:http://product.dangdang.com/29271764.html
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报