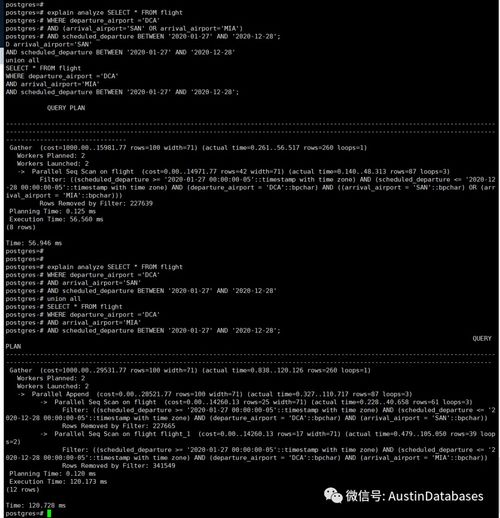
线程与进程,你真得理解了吗
- 1 进程与线程的关系和区别
- 2 并行与并发
- 3 线程共享了进程哪些资源
相信大家面试时一定没少被一个问题刁难,那就是进程和线程的区别是什么?这个问题延申开来并不像表面那么简单,今天就来深入一探。
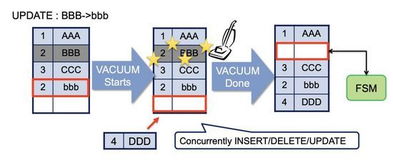
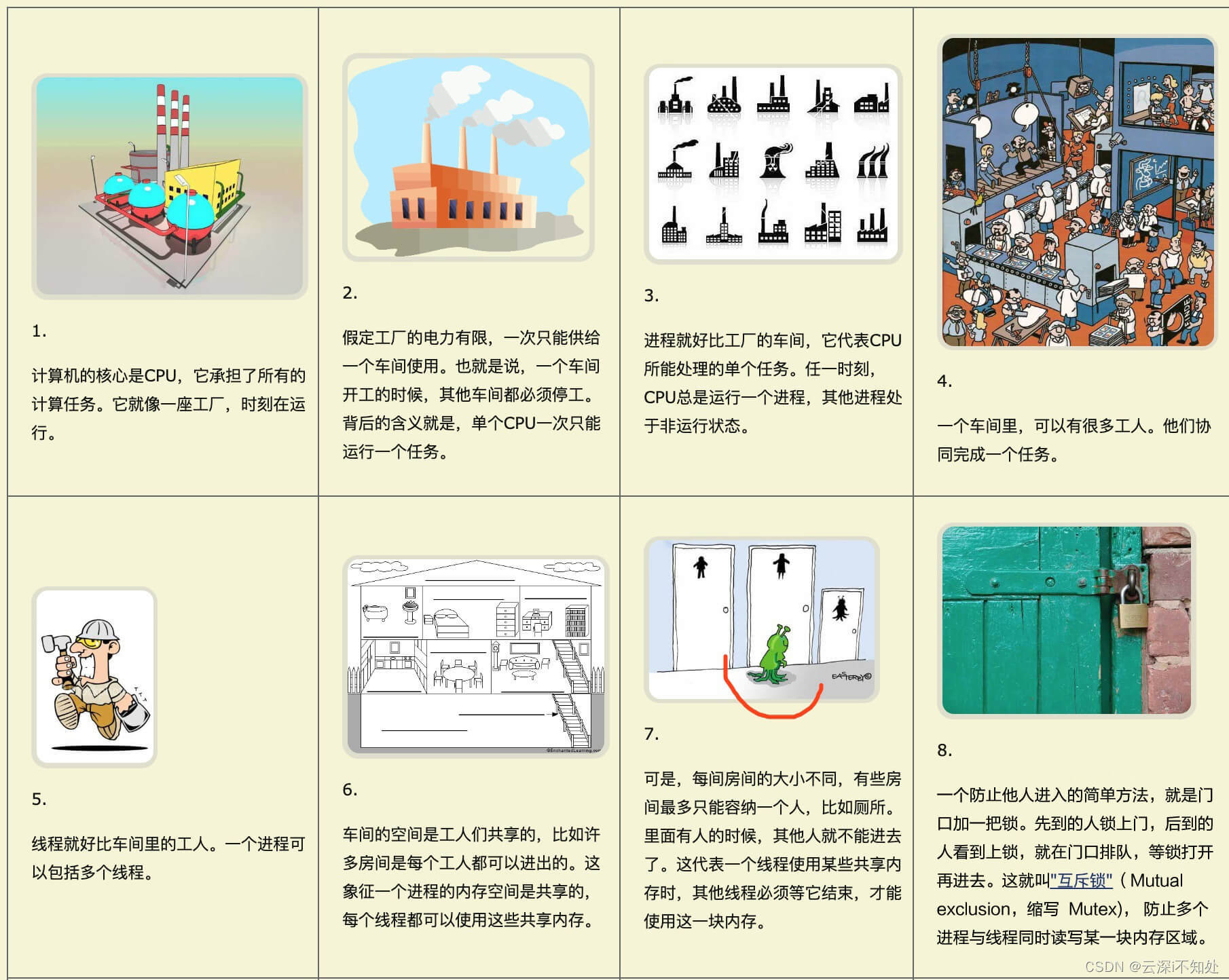
开始前先看一组非常传神的图例,相信可以帮助你更好理解进程与线程的概念:
1 进程与线程的关系和区别
什么是进程
先给一个定义:进程是一个具有一定独立功能的程序在一个数据集合上依次动态执行的过程。进程是一个正在执行的程序的实例,包括程序计数器、寄存器和程序变量的当前值。
进程有哪些特征?
- 进程依赖于程序运行而存在,进程是动态的,程序是静态的;
- 进程是操作系统进行资源分配和调度的一个独立单位(CPU除外,线程是处理器任务调度和执行的基本单位);
- 每个进程拥有独立的地址空间,地址空间包括代码区、数据区和堆栈区,进程之间的地址空间是隔离的,互不影响。
什么是线程?
进程的创建、销毁与切换存在着较大的时空开销,因此人们急需一种轻型的进程技术来减少开销。在80年代,线程的概念开始出现,线程被设计成进程的一个执行路径,同一个进程中的线程共享进程的资源,因此系统对线程的调度所需的成本远远小于进程。
进程与线程的区别总结:
-
本质区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。
-
包含关系:一个进程至少有一个线程,线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
-
资源开销:每个进程都有独立的地址空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
-
影响关系:一个进程崩溃后,在保护模式下其他进程不会被影响,但是一个线程崩溃可能导致整个进程被操作系统杀掉,所以多进程要比多线程健壮。
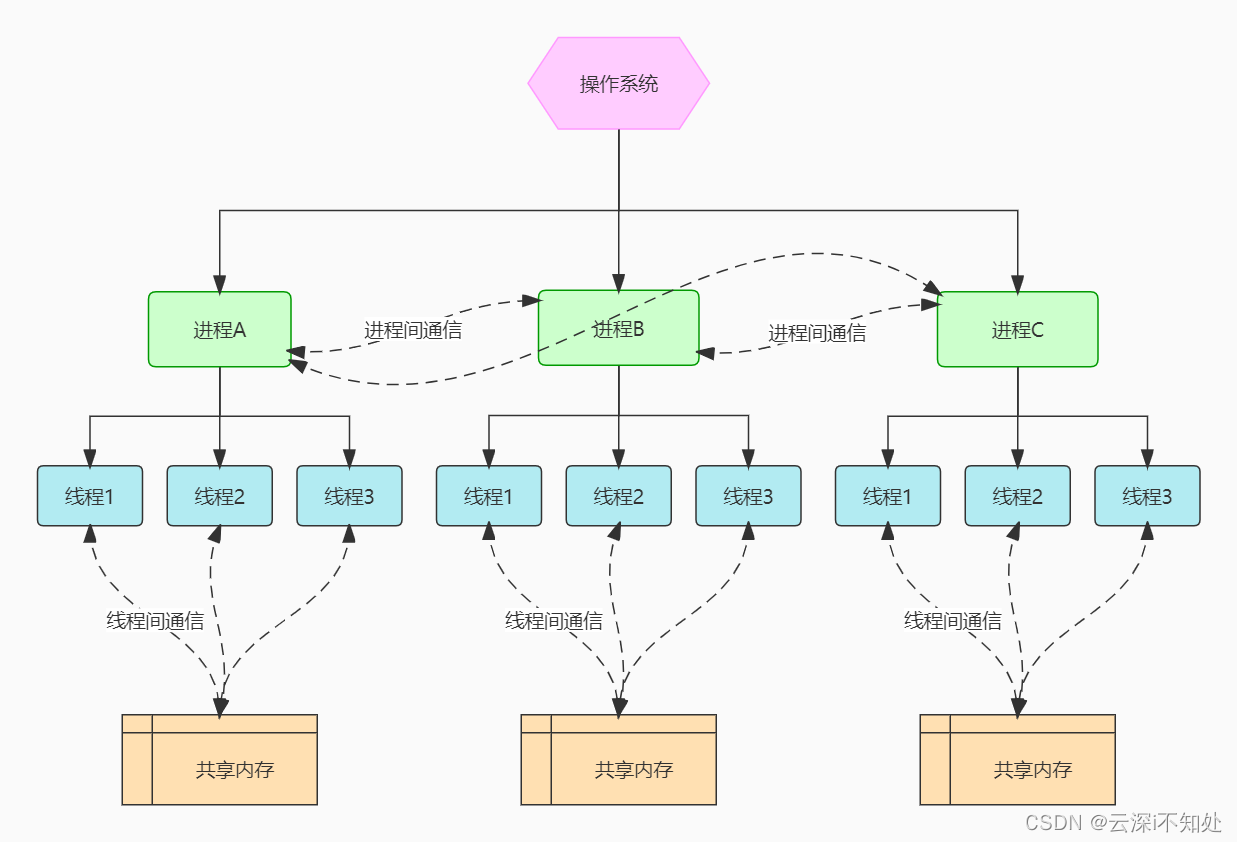
进程与线程的一个简陋模型用图表示的话,是这样的:
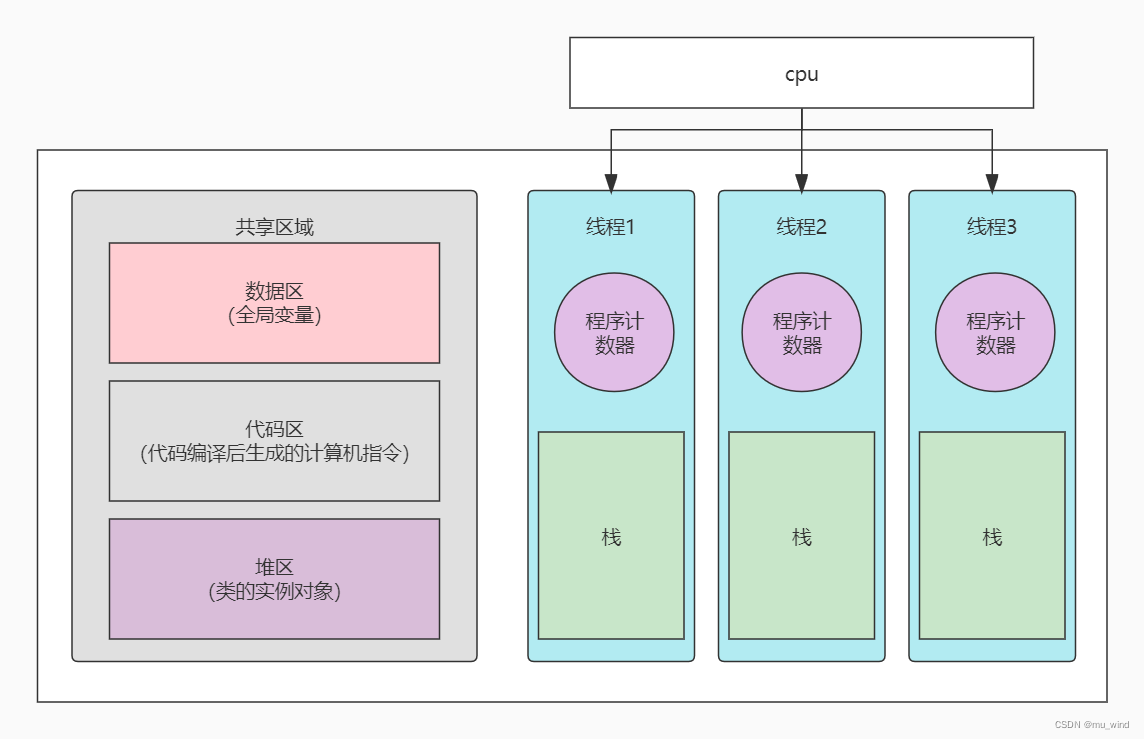
理论过于抽象难解,下面还是用大家喜闻乐见的现实中的例子去类比,没错还是工厂的例子:
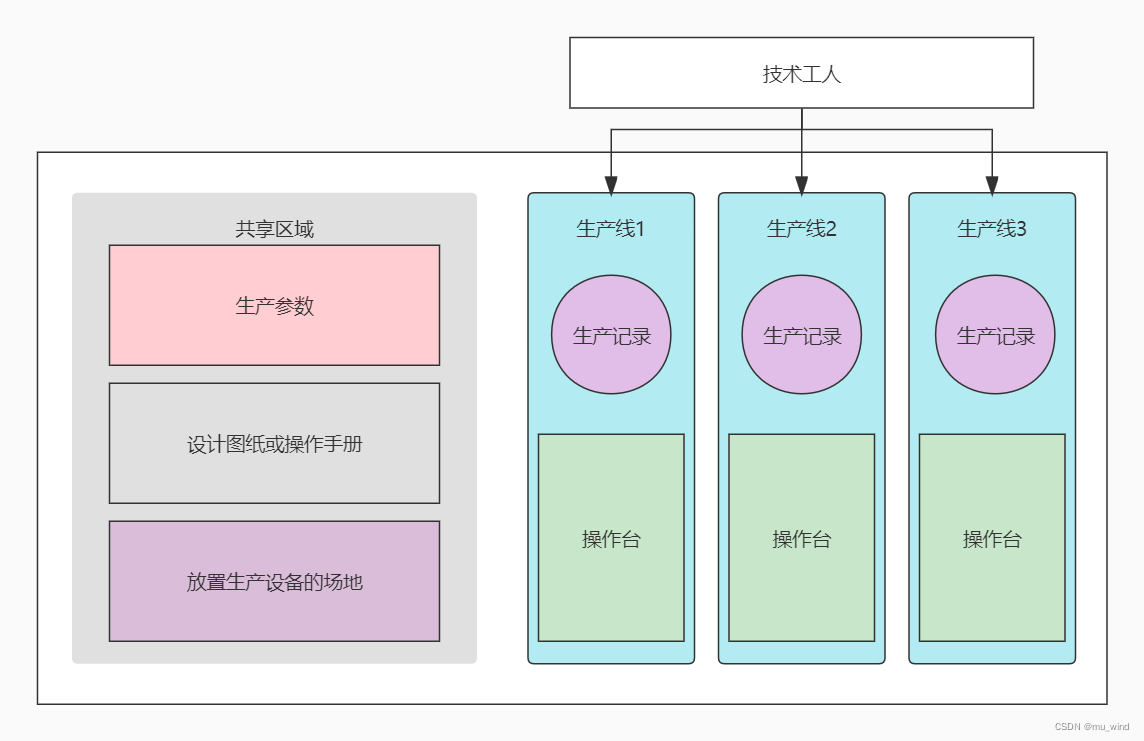
在计算机这个大工厂中,进程被比作一个车间,为生产活动提供了设计图、场地、生产线(线程)等生产要素,而线程是这个车间中的一条条生产线。生产线本身会有一个操作台,具体的零件在这里被生产。生产线必须由工人操作才能动起来,当工人来到一个生产线旁并启动它之前,必须查阅生产线的生产记录以便弄清楚这个生产线的零件加工到哪种程度了,然后才能准确地接续生产,当工人停止生产线前也必须记录这次的生产进度以备下次读取,这些进度信息可以理解为上下文,读取和记录生产进度的过程称为上下文切换。
一个工人可以在多条生产线间穿梭操作,就像CPU在不同线程间切换一样,这个动作被称为并发,与之对应的,多个工人操作多条生产线同时生产,称为并行。如果生产线不需要太多原料输入就能生产,那这种生产任务被称作CPU密集型,反之如果生产线大部分时间在等待原料的输入,那这种任务被称为IO密集型。显然,前者最好一条生产线由一个工人专管效率更高,而后一种任务,一个人在原料输入的间隙去操作其他生产线,无疑能提高工人利用率。
2 并行与并发
上面的例子提到了并发与并行,这里更精准地阐述一下。
一个基本的事实前提:一个CPU在一个瞬间只能处理一个任务。但为什么在我们人类视角,哪怕是单核心计算机也能同时做很多事情,比如同时听音乐和浏览网页,作为整个系统唯一可以完成计算任务的 CPU 是如何保证两个进程“同时进行”的呢?时间片轮转调度!
每个进程会被操作系统分配一个时间片,即每次被 CPU 选中来执行当前进程所用的时间。时间一到,无论进程是否运行结束,操作系统都会强制将 CPU 这个资源转到另一个进程去执行。为什么要这样做呢?因为只有一个单核 CPU,假如没有这种轮转调度机制,那它该去处理写文档的进程还是该去处理听音乐的进程?无论执行哪个进程,另一个进程肯定是不被执行,程序自然就是无运行的状态。如果 CPU 一会儿处理 word 进程一会儿处理听音乐的进程,起初看起来好像会觉得两个进程都很卡,但是 CPU 的执行速度已经快到让人们感觉不到这种切换的顿挫感,就真的好像两个进程在“并行运行”。

随着多核心CPU的出现,真正的并行得以实现,于是并行与并发的区别也成了面试常见题:
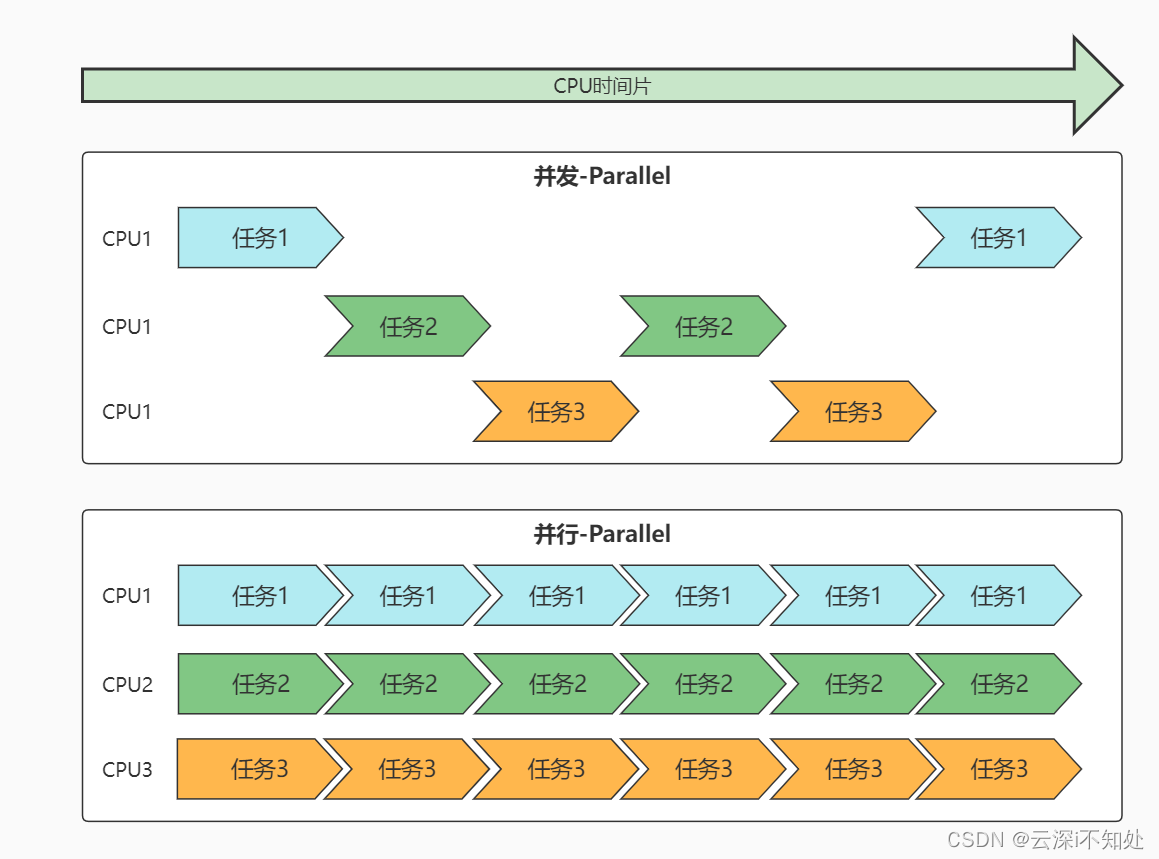
所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈上的内容,当内核需要切换到另一个进程时,它 需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
3 线程共享了进程哪些资源
这一节选自 知乎-码农的荒岛求生,文章非常精彩。
“进程是操作系统分配资源的单位,线程是调度的基本单位,线程之间共享进程资源”。
可是你真的理解了上面的那句话吗?到底线程之间共享了哪些进程资源,共享资源意味着什么?共享资源这种机制是如何实现的?
如果你没有答案的话,这篇文章就是为你准备的。
线程私有资源
函数运行时的信息保存在栈帧中,栈帧中保存了函数的返回值、调用其它函数的参数、该函数使用的局部变量以及该函数使用的寄存器信息,如图所示,假设函数A调用函数B:
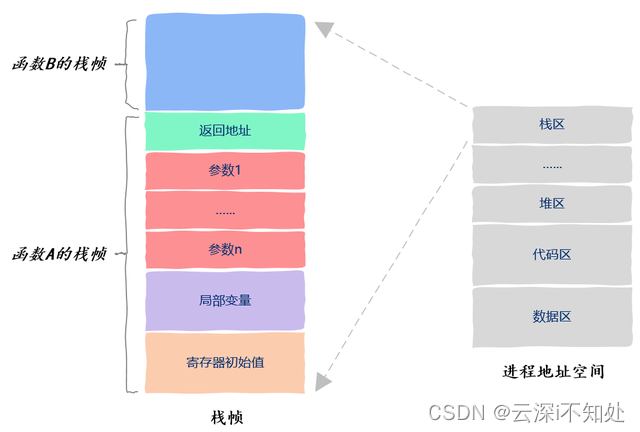
此外,CPU 执行指令的信息保存在一个叫做程序计数器的寄存器中,通过这个寄存器我们就知道接下来要执行哪一条指令。由于操作系统随时可以暂停线程的运行,因此我们保存以及恢复程序计数器中的值就能知道线程是从哪里暂停的以及该从哪里继续运行了。
由于线程运行的本质就是函数运行,函数运行时信息是保存在栈帧中的,因此每个线程都有自己独立的、私有的栈区。
同时函数运行时需要额外的寄存器来保存一些信息,像部分局部变量之类。这些寄存器也是线程私有的,一个线程不可能访问到另一个线程的这类寄存器信息。
从上面的讨论中我们知道,到目前为止,所属线程的栈区、程序计数器、栈指针以及函数运行使用的寄存器是线程私有的。
以上这些信息有一个统一的名字,就是线程上下文,thread context。
我们也说过操作系统调度线程需要随时中断线程的运行并且需要线程被暂停后可以继续运行,操作系统之所以能实现这一点,依靠的就是线程上下文信息。
现在你应该知道哪些是线程私有的了吧。除此之外,剩下的都是线程间共享资源。那么剩下的还有什么呢?还有图中的这些。
这其实就是进程地址空间的样子,也就是说线程共享进程地址空间中除线程上下文信息中的所有内容,意思就是说线程可以直接读取这些内容。
接下来我们分别来看一下这些区域。
代码区
进程地址空间中的代码区,这里保存的是什么呢?从名字中有的同学可能已经猜到了,没错,这里保存的就是我们写的代码,更准确的是编译后的可执行机器指令。
那么这些机器指令又是从哪里来的呢?答案是从可执行文件中加载到内存的,可执行程序中的代码区就是用来初始化进程地址空间中的代码区的。

线程之间共享代码区,这就意味着程序中的任何一个函数都可以放到线程中去执行,不存在某个函数只能被特定线程执行的情况。
数据区
进程地址空间中的数据区,这里存放的就是所谓的全局变量。
什么是全局变量?所谓全局变量就是那些你定义在函数之外的变量,在 C 语言中就像这样:

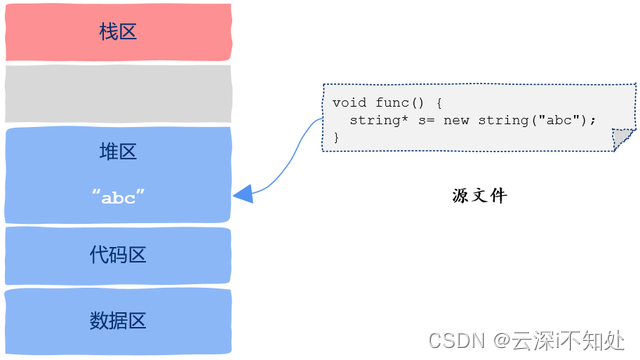
堆区
堆区是程序员比较熟悉的,我们在 C/C++中用 malloc 或者 new 出来的数据就存放在这个区域,很显然,只要知道变量的地址,也就是指针,任何一个线程都可以访问指针指向的数据,因此堆区也是线程共享的属于进程的资源。
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报