文章目录
- 每篇前言
- 一、正则表达式概述
- 1、语法大全
- 2、修饰符 - 可选标志
- 3、运算符优先级
- 4、实例简单字符匹配
- 二、re 模块
- 1、re模块操作
- 2、匹配单个字符
- 3、匹配多个字符
- 4、匹配开头结尾
- 5、匹配分组
- 6、高级用法
- re.search
- re.findall
- re.sub
- re.split
- 7、特殊语法讲解
- (?:pattern)
- (?=pattern)
- (?!pattern)
- 8、python贪婪和非贪婪
- 9、r的作用
- 10、实战案例
每篇前言
-
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、正则表达式概述
正则表达式是一个强大的字符串处理工具,几乎所有的字符串操作都可以通过正则表达式来完成,其本质是一个特殊的字符序列,可以方便的检查一个字符串是否与我们定义的字符序列的某种模式相匹配。
在Python中经常会用在:爬虫爬取数据时、数据开发、文本检索和数据筛选的时候常用正则来检索字符串等等,正则表达式已经内嵌在Python中,通过import re模块就可以使用。作为刚学Python的新手大多数都听说“正则”这个术语,本文将详细讲解从正则表达式的基础到Python中正则表达式所有语法,保证所有小白从入门到精通!!!
1、语法大全
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r't',等价于 t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
^ | 匹配字符串的开头 |
$ | 匹配字符串的末尾。 |
. | 匹配除 “n” 之外的任何单个字符。要匹配包括 ‘n’ 在内的任何字符,请使用象 ‘[.n]’ 的模式。 |
[...] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
[^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
re* | 匹配0个或多个的表达式。 |
re+ | 匹配1个或多个的表达式。 |
re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
re{n} | 匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。 |
re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。"o{0,}“则等价于"o*”。 |
re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
a| b | 匹配a或b |
(re) | 匹配括号内的表达式,也表示一个组 |
(?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
(?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
(?: re) | 类似 (…), 但是不表示一个组 |
(?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
(?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
(?#...) | 注释. |
(?= re) | 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
(?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
(?> re) | 匹配的独立模式,省去回溯。 |
w | 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
W | 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]’。 |
s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ fnrtv]。 |
S | 匹配任何非空白字符。等价于 [^ fnrtv]。 |
d | 匹配任意数字,等价于 [0-9]。 |
D | 匹配一个非数字字符。等价于 [^0-9]。 |
A | 匹配字符串开始 |
Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
z | 匹配字符串结束 |
G | 匹配最后匹配完成的位置。 |
b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘erb’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
B | 匹配非单词边界。‘erB’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
n, t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
1...9 | 匹配第n个分组的内容。 |
10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
PS:上表中re代表自己写的某一个具体匹配模式
2、修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
re.I | 使匹配对大小写不敏感 |
re.L | 做本地化识别(locale-aware)匹配 |
re.M | 多行匹配,影响 ^ 和 $ |
re.S | 使 . 匹配包括换行在内的所有字符 |
re.U | 根据Unicode字符集解析字符。这个标志影响 w, W, b, B. |
re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
3、运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
| 转义符 |
(), (?:), (?=), [] | 圆括号和方括号 |
*, +, ?, {n}, {n,}, {n,m} | 限定符 |
^, $, 任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | 替换,“或"操作字符具有高于替换运算符的优先级,使得”m|food“匹配"m"或"food”。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
4、实例简单字符匹配
| 实例 | 描述 |
|---|---|
[Pp]ython | 匹配 “Python” 或 “python” |
rub[ye] | 匹配 “ruby” 或 “rube” |
[aeiou] | 匹配中括号内的任意一个字母 |
[0-9] | 匹配任何数字。类似于 [0123456789] |
[a-z] | 匹配任何小写字母 |
[A-Z] | 匹配任何大写字母 |
[a-zA-Z0-9] | 匹配任何字母及数字 |
[^aeiou] | 除了aeiou字母以外的所有字符 |
[^0-9] | 匹配除了数字外的字符 |
二、re 模块
1、re模块操作
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为re
1. re模块的使用过程
# 导入re模块import re# 使用match方法进行匹配操作result = re.match(正则表达式,要匹配的字符串)# 如果上一步匹配到数据的话,可以使用group方法来提取数据result.group()2. 示例(匹配以itcast开头的语句)
>>> import re>>> result = re.match("itcast","itcast.cn")>>> result.group()'itcast'3. re.match(pattern, string, flags=0)
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
参数说明:
pattern: 匹配的正则表达式string: 要匹配的字符串。flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
2、匹配单个字符
在上一小节中,了解到通过re模块能够完成使用正则表达式来匹配字符串
本小节,将要讲解正则表达式的单字符匹配
| 字符 | 功能 |
|---|---|
. | 匹配任意1个字符(除了n) |
[ ] | 匹配[ ]中列举的字符 |
d | 匹配数字,即0-9 |
D | 匹配非数字,即不是数字 |
s | 匹配空白,即 空格,tab键 |
S | 匹配非空白 |
w | 匹配单词字符,即a-z、A-Z、0-9、_ |
W | 匹配非单词字符 |
示例1:.的用法
>>> import re>>> ret = re.match(".","M")>>> print(ret.group())M>>> ret = re.match("t.o","too")>>> print(ret.group())too>>> ret = re.match("t.o","two")>>> print(ret.group())two示例2:[ ]的用法
>>> import re>>> # 如果hello的首字符小写,那么正则表达式需要小写的h>>> ret = re.match("h","hello Python")>>> print(ret.group())h>>> # 如果hello的首字符大写,那么正则表达式需要大写的H>>> ret = re.match("H","Hello Python")>>> print(ret.group())H>>> # 大小写h都可以的情况>>> ret = re.match("[hH]","hello Python")>>> print(ret.group())h>>> ret = re.match("[hH]","Hello Python")>>> print(ret.group())H>>> ret = re.match("[hH]ello Python","Hello Python")>>> print(ret.group())Hello Python>>> # 匹配0到9第一种写法>>> ret = re.match("[0123456789]Hello Python","7Hello Python")>>> print(ret.group())7Hello Python>>> # 匹配0到9第二种写法>>> ret = re.match("[0-9]Hello Python","7Hello Python")>>> print(ret.group())7Hello Python>>> ret = re.match("[0-35-9]Hello Python","7Hello Python")>>> print(ret.group())7Hello Python>>> # 下面这个正则不能够匹配到数字4,因此ret为None>>> ret = re.match("[0-35-9]Hello Python","4Hello Python")>>> print(ret.group())Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group'示例3:d用法
>>> import re>>> # 普通的匹配方式>>> ret = re.match("嫦娥1号","嫦娥1号发射成功")>>> print(ret.group())嫦娥1号>>> ret = re.match("嫦娥2号","嫦娥2号发射成功")>>> print(ret.group())嫦娥2号>>> ret = re.match("嫦娥3号","嫦娥3号发射成功")>>> print(ret.group())嫦娥3号>>> # 使用d进行匹配>>> ret = re.match("嫦娥d号","嫦娥1号发射成功")>>> print(ret.group())嫦娥1号>>> ret = re.match("嫦娥d号","嫦娥2号发射成功")>>> print(ret.group())嫦娥2号>>> ret = re.match("嫦娥d号","嫦娥3号发射成功")>>> print(ret.group())嫦娥3号其他的匹配符参见后面章节的讲解
3、匹配多个字符
匹配多个字符的相关格式
| 字符 | 功能 |
|---|---|
* | 匹配前一个字符出现0次或者无限次,即可有可无 |
+ | 匹配前一个字符出现1次或者无限次,即至少有1次 |
? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
{m} | 匹配前一个字符出现m次 |
{m,n} | 匹配前一个字符出现从m到n次 |
示例1:*用法
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
>>> import re>>> ret = re.match("[A-Z][a-z]*","M")>>> print(ret.group())M>>> ret = re.match("[A-Z][a-z]*","MnnM")>>> print(ret.group())Mnn>>> ret = re.match("[A-Z][a-z]*","Aabcdef")>>> print(ret.group())Aabcdef示例2:+用法
需求:匹配出,变量名是否有效
import renames = ["name1", "_name", "2_name", "__name__"]for name in names: ret = re.match("[a-zA-Z_]+[w]*",name) if ret: print("变量名 %s 符合要求" % ret.group()) else: print("变量名 %s 非法" % name)输出结果:
变量名 name1 符合要求变量名 _name 符合要求变量名 2_name 非法变量名 __name__ 符合要求示例3:?用法
需求:匹配出,0到99之间的数字
>>> import re>>> ret = re.match("[1-9]?[0-9]","7")>>> print(ret.group())7>>> ret = re.match("[1-9]?d","33")>>> print(ret.group())33>>> ret = re.match("[1-9]?d","09")>>> print(ret.group())0 # 这个结果并不是想要的,利用$才能解决示例4:{m}用法
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
>>> import re>>> ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")>>> print(ret.group())12a3g4>>> ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")>>> print(ret.group())1ad12f23s34455ff664、匹配开头结尾
| 字符 | 功能 |
|---|---|
^ | 匹配字符串开头 |
$ | 匹配字符串结尾 |
示例1: ^用法
需要:匹配以135开头的电话号码
>>> import re>>> ret = re.match("^135[0-9]{8}","13588888888")>>> print(ret.group())13588888888>>> ret = re.match("^135[0-9]{8}","13512345678")>>> print(ret.group())13512345678# 136开头的没法匹配就会报错>>> ret = re.match("^135[0-9]{8}","13688888888")>>> print(ret.group())Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group'示例2:$
需求:匹配出163的邮箱地址,且@符号之前有4到20位,例如hello@163.com
import reemail_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]for email in email_list: ret = re.match("[w]{4,20}@163.com$", email) if ret: print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group())) else: print("%s 不符合要求" % email)输出结果:
xiaoWang@163.com 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.comxiaoWang@163.comheihei 不符合要求.com.xiaowang@qq.com 不符合要求5、匹配分组
| 字符 | 功能 |
|---|---|
| | 匹配左右任意一个表达式 |
(ab) | 将括号中字符作为一个分组 |
num | 引用分组num匹配到的字符串 |
(?P<name>) | 分组起别名 |
(?P=name) | 引用别名为name分组匹配到的字符串 |
示例1:|用法
需求:匹配出0-100之间的数字
>>> import re>>> ret = re.match("[1-9]?d","8")>>> print(ret.group())8>>> ret = re.match("[1-9]?d","78")>>> print(ret.group())78>>> # 不正确的情况>>> ret = re.match("[1-9]?d","08")>>> print(ret.group())0>>> # 修正之后的>>> ret = re.match("[1-9]?d$","08")>>> if ret:... print(ret.group())... else:... print("不在0-100之间")...不在0-100之间>>> # 添加|>>> ret = re.match("[1-9]?d$|100","8")>>> print(ret.group()) # 88>>> ret = re.match("[1-9]?d$|100","78")>>> print(ret.group()) # 7878>>> ret = re.match("[1-9]?d$|100","08")>>> # print(ret.group()) # 不是0-100之间>>> ret = re.match("[1-9]?d$|100","100")>>> print(ret.group()) # 100100示例2:()用法
需求:匹配出163、126、qq邮箱
>>> import re>>> ret = re.match("w{4,20}@163.com", "test@163.com")>>> print(ret.group())test@163.com>>> ret = re.match("w{4,20}@(163|126|qq).com", "test@126.com")>>> print(ret.group())test@126.com>>> ret = re.match("w{4,20}@(163|126|qq).com", "test@qq.com")>>> print(ret.group())test@qq.com>>> ret = re.match("w{4,20}@(163|126|qq).com", "test@gmail.com")>>> if ret:... print(ret.group())... else:... print("不是163、126、qq邮箱")...不是163、126、qq邮箱需求:不是以4、7结尾的手机号码(11位)
import retels = ["13100001234", "18912344321", "10086", "18800007777"]for tel in tels: ret = re.match("1d{9}[0-35-68-9]", tel) if ret: print(ret.group()) else: print("%s 不是想要的手机号" % tel)输出结果:
1891234432110086 不是想要的手机号18800007777 不是想要的手机号需求:提取区号和电话号码
>>> import re>>> ret = re.match("([^-]*)-(d+)","010-12345678")>>> print(ret.group())010-12345678>>> print(ret.group(1))010>>> print(ret.group(2))12345678示例3:用法
需求:匹配出<html>hh</html>
>>> import re>>> # 能够完成对正确的字符串的匹配>>> ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</html>")>>> print(ret.group())<html>hh</html>>>> # 如果遇到非正常的html格式字符串,匹配出错>>> ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")>>> print(ret.group())<html>hh</htmlbalabala># 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式>>> ret = re.match(r"<([a-zA-Z]*)>w*</1>", "<html>hh</html>")>>> print(ret.group())<html>hh</html># 因为2对<>中的数据不一致,所以没有匹配出来>>> test_label = "<html>hh</htmlbalabala>">>> ret = re.match(r"<([a-zA-Z]*)>w*</1>", test_label)>>> if ret:... print(ret.group())... else:... print("%s 这是一对不正确的标签" % test_label)...<html>hh</htmlbalabala> 这是一对不正确的标签示例4:number用法
需求:匹配出<html><h1>www.itcast.cn</h1></html>
import relabels = ["<html><h1>www.itcast.cn</h1></html>", "<html><h1>www.itcast.cn</h2></html>"]for label in labels: ret = re.match(r"<(w*)><(w*)>.*</2></1>", label) if ret: print("%s 是符合要求的标签" % ret.group()) else: print("%s 不符合要求" % label)输出结果:
<html><h1>www.itcast.cn</h1></html> 是符合要求的标签<html><h1>www.itcast.cn</h2></html> 不符合要求示例5:(?P<name>) (?P=name)用法
需求:匹配出<html><h1>www.itcast.cn</h1></html>
>>> import re>>> ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")>>> print(ret.group())<html><h1>www.itcast.cn</h1></html>>>> ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")>>> print(ret.group())Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group'注意:(?P<name>)和(?P=name)中的字母p大写

6、高级用法
re.search
re.search 扫描整个字符串并返回第一个成功的匹配;匹配成功re.search方法返回一个匹配的对象,否则返回None。
函数语法:re.search(pattern, string, flags=0)
参数说明:
pattern: 匹配的正则表达式string: 要匹配的字符串。flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例:
import re line = "Cats are smarter than dogs" searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj: print ("searchObj.group() : ", searchObj.group()) print ("searchObj.group(1) : ", searchObj.group(1)) print ("searchObj.group(2) : ", searchObj.group(2))else: print ("Nothing found!!")输出结果:
searchObj.group() : Cats are smarter than dogssearchObj.group(1) : CatssearchObj.group(2) : smarterre.match与re.search的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
import re line = "Cats are smarter than dogs" matchObj = re.match( r'dogs', line, re.M|re.I)if matchObj: print ("match --> matchObj.group() : ", matchObj.group())else: print ("No match!!") matchObj = re.search( r'dogs', line, re.M|re.I)if matchObj: print ("search --> matchObj.group() : ", matchObj.group())else: print ("No match!!")输出结果:
No match!!search --> matchObj.group() : dogsre.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
函数语法:re.findall(pattern, string, flags=0)
参数说明:
pattern: 匹配的正则表达式string: 要匹配的字符串。flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例:统计出python、c、c++相应文章阅读的次数
>>> import re>>> ret = re.findall(r"d+", "python = 9999, c = 7890, c++ = 12345")>>> print(ret)['9999', '7890', '12345']案例:多个匹配模式,返回元组列表
>>> import re>>> result = re.findall(r'(w+)=(d+)', 'set width=20 and height=10')>>> print(result)[('width', '20'), ('height', '10')]re.sub
将匹配到的数据进行替换
函数语法:re.sub(pattern, repl, string, count=0, flags=0)
参数说明(前三个为必选参数,后两个为可选参数。):
pattern: 正则中的模式字符串。repl: 替换的字符串,也可为一个函数。string: 要被查找替换的原始字符串。count: 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。flags: 编译时用的匹配模式,数字形式。
案例:
>>> import re>>>>>> phone = "2004-959-559 # 这是一个电话号码">>>>>> # 删除注释>>> num = re.sub(r'#.*$', "", phone)>>> print ("电话号码 : ", num)电话号码 : 2004-959-559>>>>>> # 移除非数字的内容>>> num = re.sub(r'D', "", phone)>>> print ("电话号码 : ", num)电话号码 : 2004959559repl 参数是一个函数
案例:将字符串中的匹配的数字乘于 2
import re # 将匹配的数字乘于 2def double(matched): value = int(matched.group('value')) return str(value * 2) s = 'A23G4HFD567'print(re.sub('(?P<value>d+)', double, s))输出结果:
A46G8HFD1134re.split
根据匹配进行切割字符串,并返回一个列表
函数语法:re.split(pattern, string[, maxsplit=0, flags=0])
参数说明:
pattern: 匹配的正则表达式string: 要匹配的字符串。maxsplit:分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
案例:以:或者空格切割字符串“info:xiaoZhang 33 shandong”
>>> import re>>> ret = re.split(r":| ","info:xiaoZhang 33 shandong")>>> print(ret)['info', 'xiaoZhang', '33', 'shandong']案例:对于一个找不到匹配的字符串而言,split 不会对其作出分割
>>> import re>>> re.split('a', 'hello world')['hello world']7、特殊语法讲解
(?:pattern)
()表示捕获分组,()会把每个分组里的匹配的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。而(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来。
>>> import re>>> a = "123abc456"# 捕获所有分组>>> ret = re.search("([0-9]*)([a-z]*)([0-9]*)",a)>>> print(ret.group(1))123>>> print(ret.group(2))abc>>> print(ret.group(3))456# 仅捕获后两个分组>>> ret = re.search("(?:[0-9]*)([a-z]*)([0-9]*)",a)>>> print(ret.group(1))abc>>> print(ret.group(2))456>>> print(ret.group(3)) # 因为第一个括号中的分组并未捕获所有只有两个分组数据Traceback (most recent call last): File "<stdin>", line 1, in <module>IndexError: no such group说明:(?:pattern)匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
(?=pattern)
正向肯定预查(look ahead positive assert),匹配pattern前面的位置。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
>>> import re>>> ret = re.search("Windows(?=95|98|NT|2000)","Windows2000")>>> print(ret.group())Windows>>> ret = re.search("Windows(?=95|98|NT|2000)","Windows3.1")>>> print(ret.group())Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group'说明:"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的 Windows,但不能匹配"Windows3.1"中的 Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?:pattern)和(?=pattern)的区别:
-
(?:pattern) 匹配得到的结果包含pattern,(?=pattern) 则不包含。如:
>>> import re# (?:pattern)>>> ret = re.search("industr(?:y|ies)","industry abc")>>> print(ret.group())industry# (?=pattern)>>> ret = re.search("industr(?=y|ies)","industry abc")>>> print(ret.group())industr -
(?:pattern) 消耗字符,下一字符匹配会从已匹配后的位置开始。(?=pattern) 不消耗字符,下一字符匹配会从预查之前的位置开始,如:
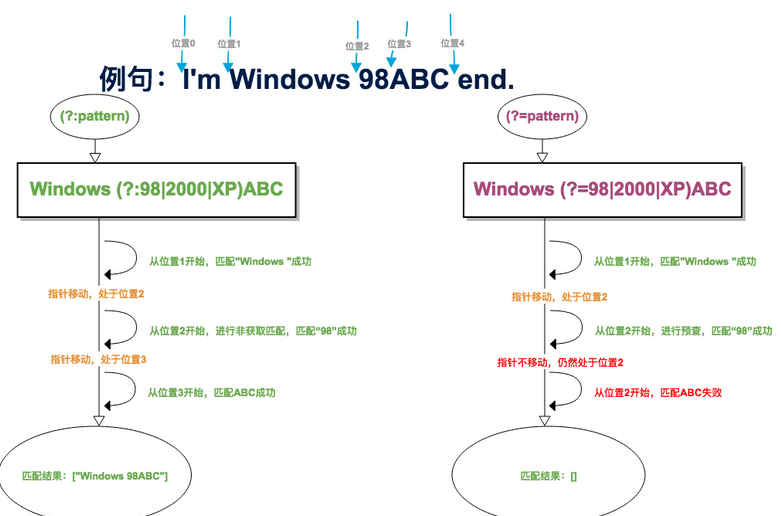
(?!pattern)
正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
>>> import re>>> ret = re.search("Windows(?!95|98|NT|2000)","Windows2000")>>> print(ret.group())Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group' >>> ret = re.search("Windows(?!95|98|NT|2000)","Windows3.1")>>> print(ret.group())Windows说明:"Windows(?=95|98|NT|2000)"不能匹配"Windows2000"中的 Windows,但能匹配"Windows3.1"中的 Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。与(?=pattern)相反
8、python贪婪和非贪婪
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
>>> import re>>> str = 'www.baidu.com/path'# ‘+’贪婪模式,匹配1个或多个>>> ret = re.match(r'w+', str)>>> print(ret.group())www# ‘+?’非贪婪模式,匹配1个>>> ret = re.match(r'w+?', str)>>> print(ret.group())w# {2,5}贪婪模式最少匹配2个,最多匹配5个>>> ret = re.match(r'w{2,5}', str)>>> print(ret.group())www# {2,5}?非贪婪模式,匹配两个>>> ret = re.match(r'w{2,5}?', str)>>> print(ret.group())ww9、r的作用
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串r'很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
>>> import re>>> mm = "c:abc">>> mm'c:abc'>>> print(mm)c:abc>>> re.match("c:",mm).group()'c:'>>> ret = re.match("c:",mm).group()>>> print(ret)c:>>> ret = re.match("c:a",mm).group()>>> print(ret)c:a>>> ret = re.match(r"c:a",mm).group()>>> print(ret)c:a>>> ret = re.match(r"c:a",mm).group()Traceback (most recent call last): File "<stdin>", line 1, in <module>AttributeError: 'NoneType' object has no attribute 'group'>>>说明:Python中字符串前面加上 r 表示原生字符串,
>>> ret = re.match(r"c:a",mm).group()>>> print(ret)c:a10、实战案例
练习1:从下面的字符串中取出文本
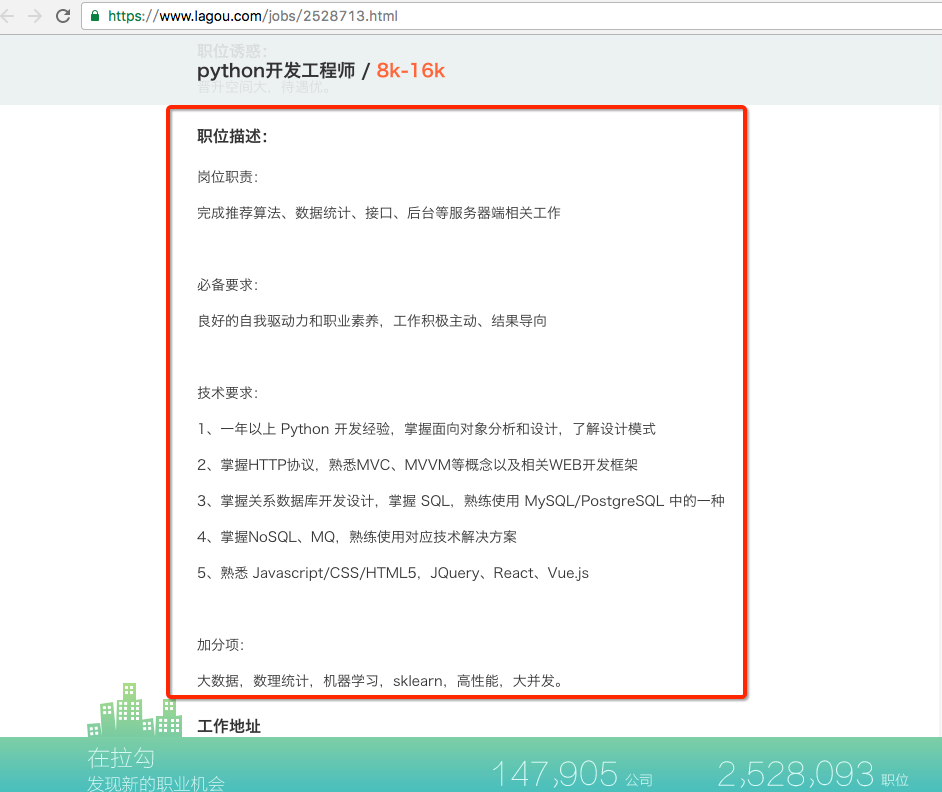
字符串:
<div><p>岗位职责:</p><p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p><p><br></p><p>必备要求:</p><p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p><p> <br></p><p>技术要求:</p><p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p><p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p><p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p><p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案</p><p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p><p> <br></p><p>加分项:</p><p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p></div>参考答案:re.sub(r"<[^>]*>| |n", "", test_str)
练习2:提取img标签中的图片链接地址
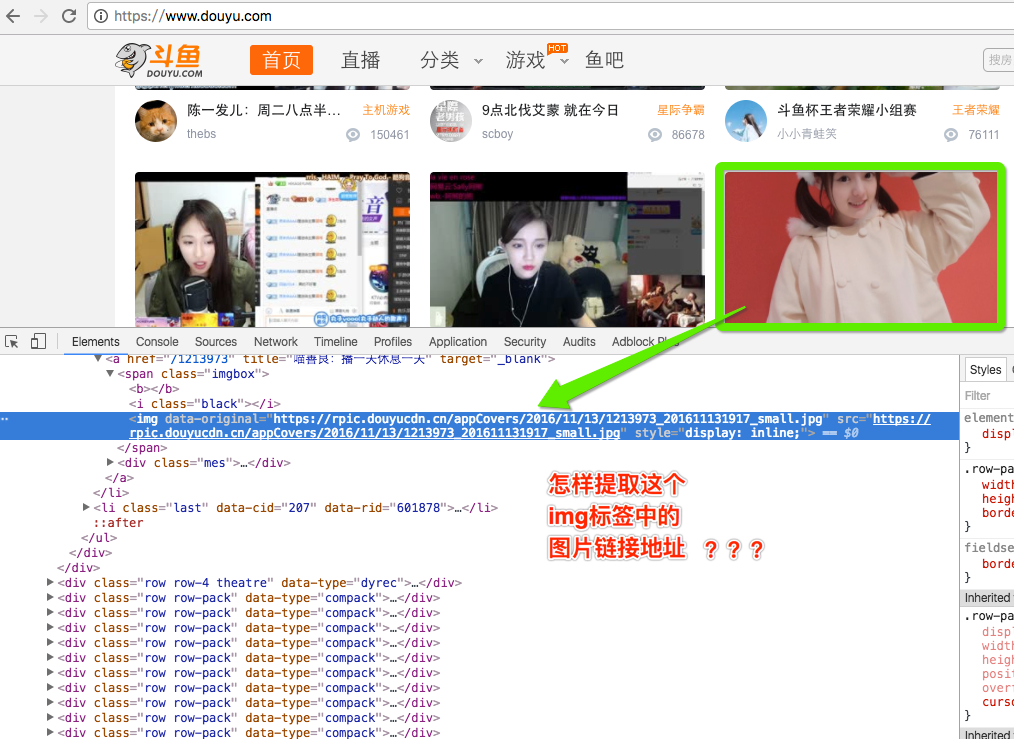
字符串为:
<img data-original="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" style="display: inline;">参考答案:re.search(r"https://.*?.jpg", test_str)
练习3:排除指定字符串
使用^(?!.*abc).*$,其中的abc为要排除的字符串
import repartten = r'^(?!.*abc).*$'strs = ['abc222', '111abc222', '111abc', 'defg']for i in strs: print(re.findall(partten, i))输出结果:
[][][]['defg']分析:
^和$表示从字符串开头开始,匹配到结尾(?!.*)表示排除形如’…abc’的部分- 后面的
.*表示’abc’后面还可以有内容
免责声明:本平台仅供信息发布交流之途,请谨慎判断信息真伪。如遇虚假诈骗信息,请立即举报
举报